Morph Selection
Only in DbVisualizer Pro
This feature is only available in the DbVisualizer Pro edition.
Introduction
The Morph Selection with Dialog in the SQL editor allows you to convert a selection of text into a delimited list with the appropriate options. Simply select text in the editor and choose Edit → Morph Selection with Dialog (or from the editor right-click menu). This will prompt you for different options about the Input Format and the Output Format, with the Output Preview overwriting the input text with the result. This lets you paste text from a Grid, Excel or some other application into the editor and then convert it into a delimited list suitable for completing a query or other documentation.
Basic Examples
Some basic examples of how various settings affect the transformations.
Detect Input Delimiter
Detect the input delimiter by counting occurrences of the default delimiters (the predefined delimiters shown in dropdown). In this case, comma (,) is the most frequent of the predefined separators (single quote (') is not a predefined delimiter).
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | ON | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
'A','B':'C','D'
Result
'A';'B':'C';'D'
Detect Numbers
Detect numbers and quote text tokens; recognized numbers (strings that match the specified number format) are not quoted.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | ON | Continuation | (N/A) |
| Grouping | , | preview setting | value |
| Decimal | . | Preview Token Count | OFF |
Input
1,000.00:two thousand:3000,00:4000
Result
1000.0;"two thousand";"3000,00";4000
Input Prefix and Suffix
Trim prefix and suffix in input tokens. Text inside prefix/suffix are treated as one token.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | ( | Suffix | None |
| Trim Suffix | ) | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
A:(B:C)
Result
A;B:C
Limit Preview
If the input is large, it may be useful to limit preview to speed up things while sorting out options. The limit is applied to number of input tokens as determined by the current settings.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | 2 |
Input
Token1:Token2:Token3
Result
Token1;Token2
Missing Input Prefix
Ignore trimming of input prefix and suffix unless both are defined (here we only defined the prefix).
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | ' | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
A:'B:C
Result
A;'B;C
Missing Input Suffix
Ignore trimming of input prefix and suffix unless both are define (here we only defined the suffix).
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | ' | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
A:'B:C
Result
A;'B;C
New Line as Input Delimiter
Transform delimiter and quote text spanning multiple lines. Since we recognize New Line as a delimiter, Token2 and Token3 are interpreted as separate tokens.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | ON | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
Token1:Token2
Token3:Token4
Result
"Token1";"Token2";"Token3";"Token4"
No Delimiters
No transformation occurs unless both input and output delimiters are defined.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | None | Delimiter | None |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
1,000.00::' one thousand '
Result
1,000.00::' one thousand '
Output Prefix
We can add a single prefix or suffix to output tokens (we can define one without the other).
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | + |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
A:B:C
Result
+A;+B;+C
Output Prefix and Suffix
We can add prefix and/or suffix to output tokens.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | [ |
| Trim Prefix | None | Suffix | ] |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
1,000.00::' one thousand '
Result
[1,000.00];[];[' one thousand ']
Output Prefix and Suffix with Text Quoting
We can both quote text and add a prefix and/or suffix to output tokens. Prefix/suffix are added to all tokens outside the quoting symbols. Since we detect numbers, the recognized number token is unformatted and not quoted.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | [ |
| Trim Prefix | None | Suffix | ] |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | ON | Continuation | (N/A) |
| Grouping | , | preview setting | value |
| Decimal | . | Preview Token Count | OFF |
Input
1,000.00:one thousand:1 000,00
Result
[1000.0];["one thousand"];["1 000,00"]
Preserve Output New Line
Transform delimiter and quote multiline text. Since we recognize and preserve New Line, we maintain a multiline output with quoted tokens.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | ON | Preserve New Line | ON |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
Token1:Token2
Token3:Token4
Result
"Token1";"Token2"
"Token3";"Token4"
Quote Output Text Tokens
Quote text tokens. Since we do not detect numbers, or strip input prefix/suffix, all tokens are quoted and prefix/suffix preserved.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
1,000.00::' one thousand '
Result
"1,000.00";"";"' one thousand '"
Repeated Delimiters
We use Space (" ") asa delimiter on an input with several repeated spaces and trim single quote (') suffix but do NOT trim whitespace. Spaces outside the prefix/suffix ar treated as a single delimiter, speces inside the prefix/suffix remain.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | Space | Delimiter | : |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | ' | Suffix | None |
| Trim Suffix | ' | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
1,000.00 ' one thousand ' 1k
Result
1,000.00: one thousand :1k
Sort Ascending
Sort tokens in ascending order on a single line.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | ASC |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
A:C:B
Result
A;B;C
Sort Descending
Sort tokens in descending order on a single line.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | DESC |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
A:C:B
Result
C;B;A
Sort Multiline Output
This is an unsupported setup: sorting is done on tokens, not lines. Sorting tokens in a multiline text would be very confusing.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | ON | Preserve New Line | ON |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | DESC |
| Trim Empty Tokens | OFF | Wrap Lines | 8 |
| Detect Numbers | OFF | Continuation | \ |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
Token1:Token2
Token3:Token4
Result
"Token1"\
;"Token2\
"
"Token3"\
;"Token4\
"
Transform Delimiter
Basic transformation of delimiters using default settings. The defined input delimiters are replaced with the defined output delimiters.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
1,000.00::' one thousand '
Result
1,000.00;;' one thousand '
Transform Delimiters on Multi Line Tokens
Transform delimiters and quote text spanning multiple lines. Since we ignore New Line, the Token2 and Token3 are interpreted as one token with two embedded New Line. The resulting output is three tokens on three lines, where the middle token includes two consecutive New Line (producing an empty line).
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
Token1:Token2
Token3:Token4
Result
"Token1";"Token2
Token3";"Token4"
Trim Input Empty Tokens
Since the input starts with a delimiter, we get an initial empty token that is trimmed. Since don't trim whitespace or consider New Line as a delimiter, the middle and trailing tokens are not trimmed.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | ON | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
: A : B :
: C : D :
Result
A ; B ;
; C ; D ;
Trim Input Empty Tokens with Include Input New Line as Delimiter
Trim empty tokens while treating New Line as a delimiter. Sine the input starts with a delimiter, we get an initial empty token that is trimmed. Since New Line is considered a delimiter, we get an empty middle token that is trimmed. Since the input ends with a delimiter and a New Line, we get a trailing empty token that is trimmed.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | ON | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | ON | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
: A : B :
: C : D :
Result
A ; B ; C ; D
Trim Input Whitespace
Trim whitespace outside any prefix/suffix (whitespace inside prefix/suffix is preserved). Since New Line is considered as whitespace, we get an empty middle token.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | ON | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
: A : B :
: C : D :
Result
;A;B;;C;D;
Trim Input Whitespace and Empty Tokens
Trim whitespace outside any prefix/suffix (whitespace inside prefix/suffix is preserved). Since the input starts with a delimiter, we get an initial empty token that is trimmed. Since New Line is considered as whitespace, we get an empty middle token that is trimmed. Since the input ends with a delimiter and a New Line, we get a trailing empty token that is trimmed.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | ON | Sort | None |
| Trim Empty Tokens | ON | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
: A : B :
: C : D :
Result
A;B;C;D
Trim Input Whitespace and Empty Tokens with Input New Line as Delimiter
Trim whitespace and Empty Tokens while recognizing New Line as an input delimiter. Since the input starts with a delimiter, we get an initial empty token that is trimmed. Since New Line is considered as whitespace, we get an empty middle token that is trimmed. Since the input ends with a delimiter and a New Line, we get a trailing empty token that is trimmed.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | ON | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | ON | Sort | None |
| Trim Empty Tokens | ON | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
: A : B
C : D :
Result
A;B;C;D
Trim Input Whitespace and Empty Tokens with Input New Line as Delimiter Preserved in Output
Trim whitespace and Empty Tokens while recognizing New Line as a delimiter and preserving it in the Output. Since the input starts with whitespace and a delimiter, we get an initial empty token that is trimmed. Since New Line is considered as whitespace, we get an empty middle token that is trimmed. Since the input ends with a delimiter and a New Line that is trimmed, we get a trailing empty token that is trimmed. Since we preserve New Line in Output, we get the first two tokens (A and B) on the first line and the last two tokens (C and D) on the second line.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | ON | Preserve New Line | ON |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | None |
| Trim Whitespace | ON | Sort | None |
| Trim Empty Tokens | ON | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
: A : B
C : D :
Result
A;B
C;D
Trim Input Whitespace with Prefix and Suffix
Whitespace is trimmed before trimming prefix/suffix - whitespace inside prefix/suffix is preserved.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | ( | Suffix | None |
| Trim Suffix | ) | Quote Text Value | None |
| Trim Whitespace | ON | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
1,000.00: ( 1k ) : one thousand
Result
1,000.00; 1k ;one thousand
Wrap Output Lines
Wrap lines at specified length, including any prefix, suffix or quoting symbols. Wrapping does not observe any tokens or words, it breaks here at specified length.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | 8 |
| Detect Numbers | OFF | Continuation | None |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
Token1:Token2:Token3
Result
"Token1"
;"Token2
";"Token
3"
Wrap Output Lines with Continuation Symbol
Wrap a multiline output text with a symbol terminating each line that continues on the next line. Regular line breaks (not resulting from wrapping) are not terminated with the wrapping symbol.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | : | Delimiter | ; |
| Include New Line | ON | Preserve New Line | ON |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | OFF | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | 8 |
| Detect Numbers | OFF | Continuation | \ |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
Token1:Token2
Token3:Token4
Result
"Token1"\
;"Token2\
"
"Token3"\
;"Token4\
"
Use Cases
A few "real world" use cases of how to use the Morph function to transform input data into the desired output format.
Morph IN Clause Data to CSV Format
I have an IN clause with text values that I want to use as unquoted data in a CSV file. I need to trim whitespace and prefix/suffix before transforming the input delimiter to my desired output delimiter.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | , | Delimiter | ; |
| Include New Line | OFF | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | ' | Suffix | None |
| Trim Suffix | ' | Quote Text Value | None |
| Trim Whitespace | ON | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
'BETTE', 'CHRISTIAN', 'GRACE', 'JENNIFER', 'JOE', 'JOHNNY', 'KARL', 'MATTHEW', 'UMA', 'ZERO'
Result
BETTE;CHRISTIAN;GRACE;JENNIFER;JOE;JOHNNY;KARL;MATTHEW;UMA;ZERO
Morph Table Data into CSV Format
I copied a table from a web page into SQL Commander and want to save it as a file that can be used for import. I want the data in CSV format, lines sorted, text values quoted and any empty lines suppressed.
Input is tab separated, not quoted, in random order and a mix of strings and numbers. Output is not sorted, separated by semi-colon and all text values are quoted.
Note: it is not possible to sort the output lines. The morph operation is about tokens, not lines.
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | Space | Delimiter | ; |
| Include New Line | ON | Preserve New Line | ON |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | " |
| Trim Whitespace | ON | Sort | None |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | ON | Continuation | (N/A) |
| Grouping | , | preview setting | value |
| Decimal | . | Preview Token Count | OFF |
Input
1 PENELOPE GUINESS
6 BETTE NICHOLSON
3 ED CHASE
7 GRACE MOSTEL
2 NICK WAHLBERG
4 JENNIFER DAVIS
5 JOHNNY LOLLOBRIGIDA
8 MATTHEW JOHANSSON
12 KARL BERRY
9 JOE SWANK
11 ZERO CAGE
10 CHRISTIAN GABLE
13 UMA WOOD
Result
1;"PENELOPE";"GUINESS"
6;"BETTE";"NICHOLSON"
3;"ED";"CHASE"
7;"GRACE";"MOSTEL"
2;"NICK";"WAHLBERG"
4;"JENNIFER";"DAVIS"
5;"JOHNNY";"LOLLOBRIGIDA"
8;"MATTHEW";"JOHANSSON"
12;"KARL";"BERRY"
9;"JOE";"SWANK"
11;"ZERO";"CAGE"
10;"CHRISTIAN";"GABLE"
13;"UMA";"WOOD"
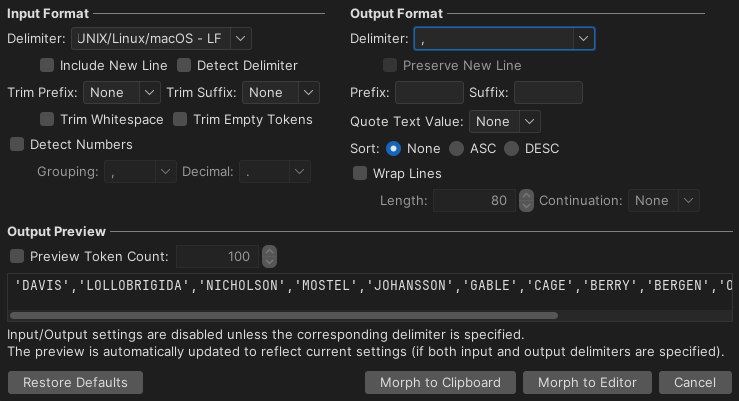
Morph Table Data to IN Clause Format
I copied a column from Excel into SQL Commander and want to convert it to a string that I can use as an IN clause in a SQL Query.
I want the data comma separated with a space (, ), all values quoted, whitespaces trimmed and any empty lines suppressed. Since there is no predefined delimiter that includes a space after the comma, I type this delimiter directly in the combo box 1.
Input is tab separated, not quoted, in random order and a mix of strings and numbers. Output is sorted, separated by semi-colon and all text values are quoted.
1 it is hard to see the trailing space in the settings below
Settings
| input setting | value | output setting | value |
|---|---|---|---|
| Delimiter | UNIX/Linux/macOS - LF | Delimiter | , |
| Include New Line | ON | Preserve New Line | OFF |
| Detect Delimiter | OFF | Prefix | None |
| Trim Prefix | None | Suffix | None |
| Trim Suffix | None | Quote Text Value | ' |
| Trim Whitespace | ON | Sort | ASC |
| Trim Empty Tokens | OFF | Wrap Lines | OFF |
| Detect Numbers | OFF | Continuation | (N/A) |
| Grouping | (N/A) | preview setting | value |
| Decimal | (N/A) | Preview Token Count | OFF |
Input
JENNIFER
JOHNNY
BETTE
GRACE
MATTHEW
JOE
CHRISTIAN
ZERO
KARL
UMA
Result
'BETTE', 'CHRISTIAN', 'GRACE', 'JENNIFER', 'JOE', 'JOHNNY', 'KARL', 'MATTHEW', 'UMA', 'ZERO'