intro
Messy queries are not news to any DBA. As time flies, more work piles up, and more data is written to the database that‘s supporting the application the company you work with is selling, the database, and, consequently, associated queries are bound to become a little harder to manage.
Messy queries can be noticed by assessing:
You get the point – messy queries that weren’t that well thought out are a problem on many fronts: customers will complain, our applications will grind to a halt… The work of developing the application will be impacted. However, there is a simple way to fix these issues – choosing a professional SQL client like DbVisualizer will help us write efficient queries and make sure that our application runs like the wind.
What Are SQL Clients And How Can They Help?
SQL clients target multiple database management systems (think MySQL, PostgreSQL, MongoDB, Oracle, and the like) with an aim to simplify our work with databases – all of them are, of course, built differently, but good SQL clients come with the following features:
If you are looking for an easy and powerful SQL client and database manager, then you've got to try DbVisualizer. It connects to nearly any database.
At the end of the day, SQL clients shoot multiple rabbits with one bullet – they help us manage the data within our databases and fix messy queries too – everything under one roof. Keep reading and we’ll tell you how exactly it all works.
Fixing Messy Queries with DbVisualizer
To help DbVisualizer gain insight into our queries, we first need to import a database instance into the tool – if you’re running DbVisualizer for the first time, you can do that by following the instructions on the screen, and if you’ve been working with DbVisualizer for a longer period, select the database you want to work with on the left-hand side or create a new database connection as shown below and you should be good to go:

Once you‘ve imported the database into DbVisualizer, confirm it‘s able to connect to the database instance by either looking for the checkmark towards the left side of the name of the DBMS, or expanding the connection in question. If the connection is successful, you should be able to see a list of databases:

Expand a database you want to work with, then head over to the table that is causing problems.
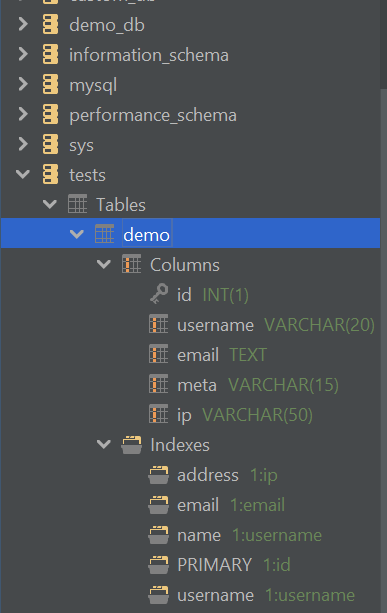
Now we can get to work. Big things start small, remember? Messy queries start with the data types and indexes being defined improperly or not being defined at all – in this case, the table we are looking at:
Understanding the database structure is key to fixing messy queries because the data that is selected and the indexes on the column containing the data directly impact the speed of the queries. Let‘s assume we‘re looking into the performance of a SELECT query. Suppose our problematic query looks like so:
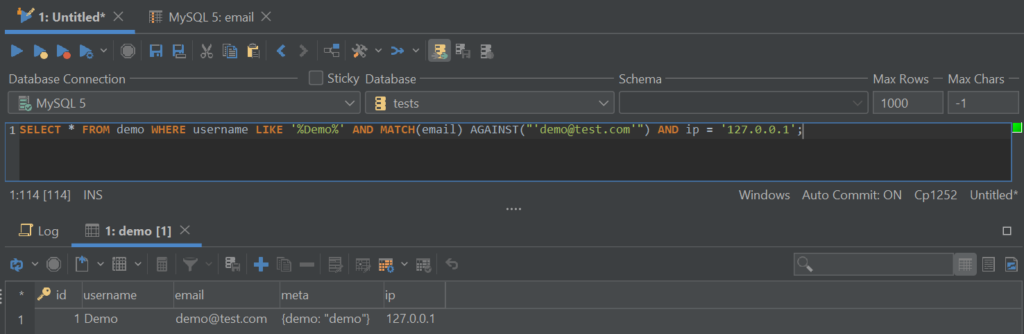
A DBA will instantly notice that there are a couple of things that this query does:
DBAs will know that all of them are problematic in their own regard since all of them make the query slow. Here‘s why:
However, chances are that you‘re not a DBA and you might not know all of the details – that‘s where SQL clients such as DbVisualizer step in.
Fixing Issues with DbVisualizer
Head back to the left side of the tool – remember the columns and indexes? Start by exploring those – click on each of the columns one by one to see how they are built. You will see something similar to the screenshot below:

For performance reasons, note down the values of „size“, „type“, and „nulls.“ Then explore indexes and triggers if there are any (for this specific example, note that the name of the index and the column can differ):
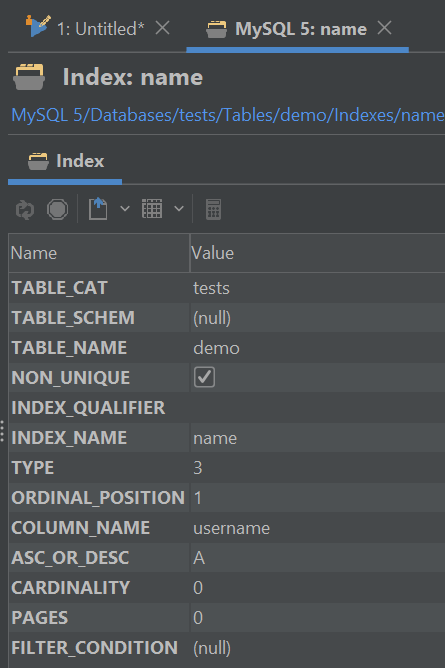
Performing basic check-ups on the structure of the table, indexes, and triggers within them is key to fixing the mess our queries have made – couple that with basic knowledge on the database front, and you should be good to go!
For now, though, let‘s come back to our example above. On the same column, we see that there is an index called username, it‘s unique and ascending, and we also see that there aren‘t any unique values in it as of yet. All of those things should raise two questions:
Answer those questions – the answers can lead to actions that improve query speed or assist us in other areas: in this specific case, raising the length from 20 to 255 (the maximum value) could mean less customer complaints due to longer usernames not being registered without a strain on the database.
As we inspect other columns, we may see a different pattern – the columns may have unique values in them (cardinality), their length could be bigger, the default value of the column could be NULL instead of an empty one, etc. That‘s why no matter how powerful a SQL client is, you would still need to combine your knowledge of databases to push them to their maximum potential. When you find yourself rebuilding messy queries, keep in mind the following things:
Keep the advice above in mind when reworking your queries with DbVisualizer – many of the issues you‘re facing can be solved by wrapping your head around one or more of these points. However, understanding them alone is not enough to fix the mess that your queries have made; understanding the structure of your tables (the left side of DbVisualizer), properly writing queries (the SQL commander option in DbVisualizer), and monitoring the speed of your queries (the bottom right side of DbVisualizer) are all essential for the brighter future of your database and application.

We hope that this article has been informational and helped you fix issues surrounding your queries or at least wrap your head around them. Come back to the blog for more similar content, and until next time.

