Importing Table Data
Only in DbVisualizer Pro
This feature is only available in the DbVisualizer Pro edition.
You can import data using the Import Table Data wizard.
You can import data from a file into an existing table or to a new table. The import source can be either a CSV file or an Excel file (.xls or .xlsx). The steps are almost identical:
- Select the table node for the table you want to import to, or the Tables node if you are importing to a new table, in the Databases tab tree,
- Open the Import Table Data wizard from the right-click menu,
- Specify the input file on the first wizard page (CSV or Excel file),
- [Excel only]: If the input file is an Excel file, you are asked to choose the Excel sheet to import on the next page.
- Specify file format and other options,
- Specify data formats and the data type per column,
- Adjust details about the destination table,
- Click Import on the last page.
Instead of choosing Import Table Data from the right-click menu, you can drag and drop a file from the operating system's file manager on the Tables node or a table node.
How many INSERT statements to execute during the import process before committing the changes can be specified in the Properties tab for the connection, in the Transaction category.
Input File Format and Other Options
On the File Format page, you specify what and how the data in the source file should be imported. This includes specifying what row to start the import from and if empty rows should be skipped.
DbVisualizer supports import of CSV and Excel files (both the .xslx and the legacy .xsl file formats).
CSV format page
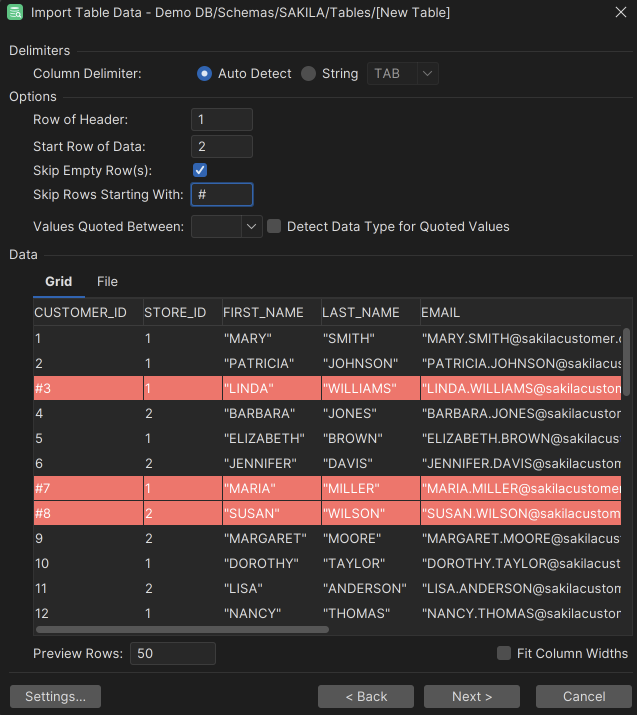
In the Delimiters section, define the character that separates the columns in the file. If you enable Auto Detect, DbVisualizer tries to auto detect which delimiter is used. Examples of auto detected delimiters are:
- comma ","
- tab "TAB"
- semicolon ";"
- percent "%"
- pipe "|"
- Using Unicode Code Points such as
\u2656.
You can specify any character sequence as a delimiter, but it must not contain more than four characters.
You can use the Options area to further specify how to read the input file. For instance, you can skip rows that start with a specific string (e.g. comments) or strip quotes from text data. If you leave Values Quoted Between empty, data will be imported as is (which may cause problems if you have text strings that include the column delimiter).
The Data section at the bottom of the page shows a preview of the parsed data in the Grid tab and the original source file in the File tab. If a row in the Grid tab is red, it indicates that the row will be ignored during the import process. This happens if any of the Options settings result in rows not being qualified.
If the checkbox Detect Data Type for Quoted Values is checked the data type is also detected for that value. E.g a value "1" will be detected as a Number and not a String.
Excel format page
The Excel format page is very much like the CSV format page.
As Excel is from start organized in columns and rows the Column delimiter setting is not applicable to Excel files. The Skip Rows Starting With and the Text Quoted Between options are also not supported for Excel.
As shown in the snapshot below there is no File tab for Excel files.
The Grid tab shows a preview of the data, just as in the CSV case.

Data Formats and Data Type Per Column
The Data Formats page is used to define formats for some data types. The first row in the preview grid contains a data type drop-down lists. DbVisualizer tries to determine the data type for each column by looking at the value for the number of rows specified as Preview Rows. If this data type is incorrect for a column, use the drop-down lists to select the appropriate type.

If you need to change the data type for a number of columns, e.g. set them all to String, you can Copy/Paste the data type. First change it for one of the columns using the drop-down, select and copy that new data type value and then select the data type for all other columns and use paste to change them all at once. If you make a mistake, you can change the Preview Rows value to let DbVisualizer determine the types again.
If you import to an existing table, there is yet another way to adjust the data types for the file columns, described in the next section.
Matching Columns and Data Types for an Existing Table
When you are importing to an existing table, the Import Destination page provides two options: Grid and Current Database Table. You can use the Grid choice to import the data into a grid that is presented in its own window in DbVisualizer if you just want to just process the data in some way without saving it in the database.
When the Current Database Table choice is selected, the page shows information about the table into which the data will be imported in the Map Table Columns with File Columns grid shows the columns in the selected database table and the columns in the source file.

DbVisualizer automatically associates the columns in the source file with the columns in the target table in the order they appear. If the columns appear in a different order in the file than in the table, but they are named the same, you can use the auto-mapping menu in the upper right corner of the Map Table Columns with File Columns grid to automatically map the columns by name. Map by Column Name and Map by Column Index do exactly what it sounds like. Map File Data Type = Table Data Type sets the File Data Type for each column to the type of the corresponding table column.
If the column names are different between the file and the table and also appear in different order, you can manually map them using the drop-down lists in the File Column Name field. Choose the empty choice in the columns drop-down to ignore the column during import.
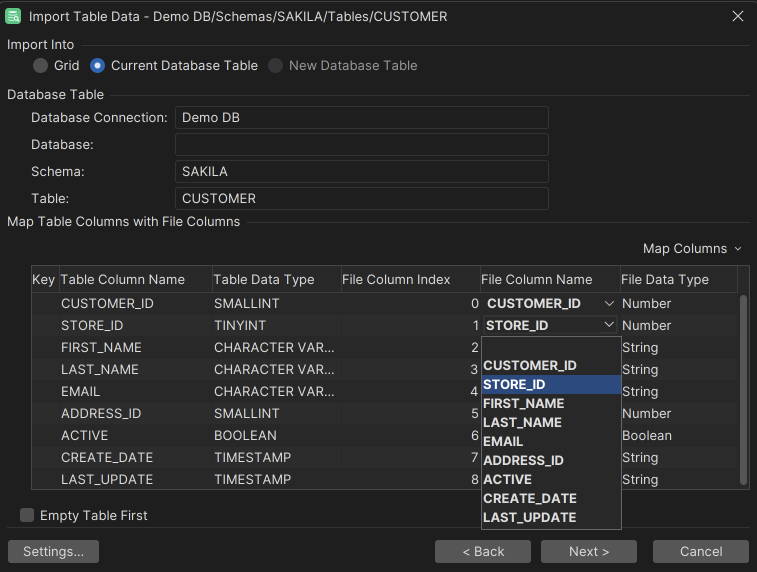
You can use copy/paste of the values in the File Column Name and File Data Type fields to quickly fill the selection of cells instead of manually selecting the correct data in the drop-downs.
There are two checkboxes at the bottom of the page:
- Use Delimited Identifiers: check this if you want the SQL statements for importing the table to use delimited identifiers; in other words, if you want to use table and column names with special characters, mixed case, or anything else that requires delimited (quoted) identifiers.
- Empty Table First: check this if you want to clear/empty the table before import. Choose between Truncate or Delete. Truncate is faster as it usually will clear the data without occupying the rollback management in the database.
Adjusting Table Declaration for a New Table
When you import into a new table, the Import Destination page provides two options: Grid and New Database Table.
- Use the Grid choice to import the data into a grid if you just want to just process the data in some way without saving it in the database. The data is presented in its own window in DbVisualizer and can be formatted, filtered, viewed and exported again.
- Use the New Database Table choice to import into a table; you are presented with a field for the table name and a number of tabs for column and constraint declarations. The Columns tab is filled out based on the source data and the data types from the Data Formats page.
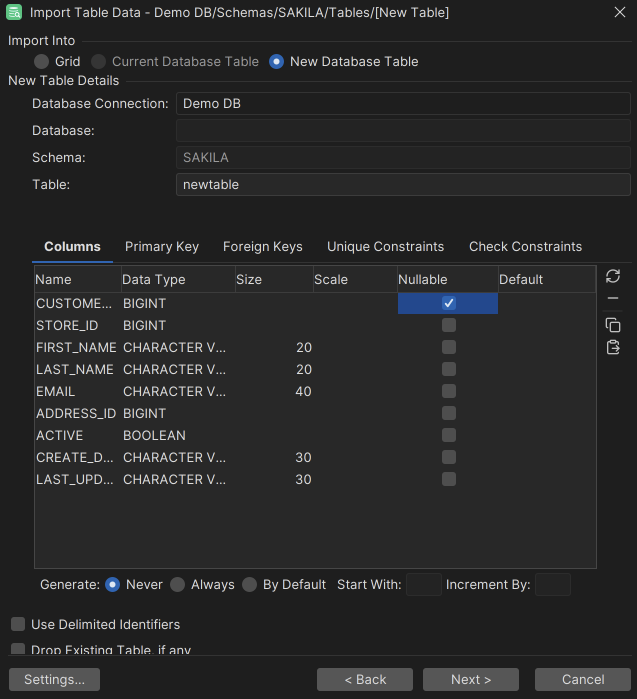
Note that it is not always possible to find a database specific type for the data format specified on the Data Format page. You must then pick the correct type from the Data Type drop-down menu. The size for string column types may also need to be adjusted. By default, the size is set to the maximum number of characters found for the column in the number of rows specified as Preview Rows, adjusted up to the next power of ten. You can ignore certain columns by removing them in the Columns tab. Keys and other constraints can be created using the other tabs.
You can go back to the Data Format page and increase the Preview Rows value if you believe that it will help DbVisualizer to pick better defaults. If you do so, you need to click the Reload button when you come back to this page to rescan the source data and get new default values.
If you make a mistake or if the import fails and you have to go back and make adjustments before you import again, make sure you enable Drop Existing Table, if any. It is disabled by default to prevent you from accidentally dropping an existing table when you intend to import to a new table, but if the import fails, the new table may already have been created so it needs to be dropped before a new table with your adjusted input can be created.
There is also a Use Delimited Identifiers checkbox. Check this box if you want the SQL statements for importing the table to use delimited identifiers; in other words, if you want to use table and column names with special characters, mixed case, or anything else that requires delimited (quoted) identifiers.
Importing Binary/BLOB and CLOB Data (CSV and SQL Only)
If you have exported data to a CSV file using DbVisualizer, use the Import Table Data feature to import it. On the Data Format page, ensure that the format for the source file column is set to BLOB or CLOB.

If you have exported Binary/BLOB and CLOB data as an SQL script, you just run the script in the SQL Commander to import it. When the SQL Commander encounters a variable that refers to a file, it reads the file and inserts the content as the column value.
Running the import
The last wizard page contains some basic settings for the import.
- Import All rows/Import: Used to limit the number of rows to import
- Single Inserts: If checked, each row will be sent to the database and inserted one-by-one. The commit interval specifies how often a commit should be performed.
- Batch Import: If checked the import will be performed in batches. This may improve performance considerably making the import faster. Note that different databases/drivers may have different level of support for batch import. The rows per batch/commit setting controls how large batches should be sent to the database. There will be a commit for each batch.
- Keep Window After import: If checked the Import window will remain open after import. If the import fails the window will always remain open.
- Stop On Error: If checked the import will stop if an error occurs.
Saving And Loading Settings
If you often use the same settings, you can save them as the default settings for this assistant. If you use a number of common settings, you can save them to individual files that you can load as needed. Use the Settings drop-down button menu to accomplish this:
- Save as Default Settings Saves all format settings as default. These are then loaded automatically when open an Export Schema dialog
- Use Default Settings Use this choice to initialize the settings with default values
- Remove Default Settings Removes the saved defaults and restores the regular defaults
- Load... Use this choice to open the file chooser dialog, in which you can select a settings file
- Save As... Use this choice to save the settings to a file
- Copy Settings to Clipboard Copies the settings to the system clipboard
Other Ways to Import Table Data
If you have a script containing INSERT statements for all data, you can execute it in the SQL Commander.
There is also the @import client-side command that is executed in the SQL Commander. With it you can define the import setup using commands only and let it run both in the DbVisualizer GUI or in the command-line interface for DbVisualizer, dbviscmd.
The special LOAD DATA option for MySQL, MariaDB and SingleStore is available in DbVisualizer, and it enables fast import from a local or server file. To open the Load Table Data dialog, right-click on a table and select Import Table Data->Load Table Data. This option requires special driver property setting and may also require privileges on the server.
Known limitations
- Excel files cannot contain CLOB/BLOB type of data (e.g. images etc). Cells with this kind of data are imported as empty.
- There is a size limitation when importing Excel files with the
.xlsfilename extension. The size limitation is roughly 20 megabytes, depending on your configuration and how much memory is used for other things. Increasing DbVisualizer max memory may allow you to import larger files.