intro
In this tutorial, you will learn about the different types of data structures, such as trees, linked lists, and hash tables, and how they can be used to organize and access data. You will also learn how to design and write efficient SQL queries to interact with these data structures. By the end of this tutorial, you will have the skills and knowledge to confidently implement data structures in SQL databases.
Data structures play a key role in the world of computers. They are a practical and effective way of storing data. Without them, the world of computing would be much harder as it would be difficult to manage large amounts of data and create software that runs smoothly.
This tutorial will introduce you to some popular data structures and guide you on how to implement them for SQL databases.
What are Data Structures?
Data structures are a fundamental part of any digital system, providing a way to organize and store data in an efficient manner. They help reduce the time it takes to access and use data, as well as the amount of memory needed to store it. By using data structures, data can be quickly searched, sorted, and retrieved. They are a fundamental component of computer science and software engineering. Data structures are also used to represent relationships between data elements, such as parent-child relationships, or to represent the structure of a graph.
Depending on how the data is stored and accessible, data structures are often classified as linear or non-linear. Linear data structures, such as an array, stack, or queue, are made up of a series of components. Non-linear data structures, such as a tree or graph, are made up of nodes that are linked to one another.
Since data structures are critical components of every software or application, it would be difficult to store and retrieve data in any meaningful way without them. Understanding the many types of data structures and how they function is therefore a key aspect of software engineering.
Useful Data Structures for SQL Databases
When working with SQL databases, there are several different data structures that can be used to store and organize data. The most common data structures used in SQL databases are:
1. Stacks (LIFO)
Stacks are a data structure that uses the Last In First Out (LIFO) principle. This means that the last item that was added onto the stack (the element at the top of the stack) is the first one that can be removed. A stack is like a stack of books or a stack of plates. For example, a stack of books would be organized such that the most recently added book is on top and the oldest book is at the bottom.
2. Queues (FIFO)
Queues are a data structure that uses the First In First Out (FIFO) principle. This means that the first item that was added to the queue (the element at the front of the queue) is the first one that can be removed. A queue is like a line of people waiting for an elevator. For example, the first person that got in line would be the first one that gets to ride the elevator.
3. Trees
Trees are a data structure that is made up of nodes connected by edges. Each node can have any number of children nodes, but only one parent node. The nodes at the bottom of the tree are called leaves, while the nodes at the top of the tree are called the root. Trees are a widely used data structure in computer science, and they have many applications, particularly in searching and sorting algorithms. An example of this is binary search trees, which are organized in such a way that all elements left of a node are smaller than the node, and all elements to the right of the node are larger than it. This structure allows for faster searching, as the algorithm only needs to search the left or right subtree depending on the value it is looking for.
4. Hash Tables

Hash tables are data structures that use a key-value pair to store data. A hash table is like a dictionary, with the key being the word and the value being the definition. The key is used to calculate an index in the hash table, which is then used to look up the value. Hash tables are efficient for looking up values, but they can be slow for inserting or deleting elements. For example, if a company is using a hash table to track customer information. When a customer calls in, their customer ID is used to look up their information in the hash table. This lookup is quick and efficient. However, if a customer changes their address, the hash table must be updated to reflect the change. This insertion or deletion of an element can be slow, as the entire hash table must be reorganized to reflect the change.
5. Graphs
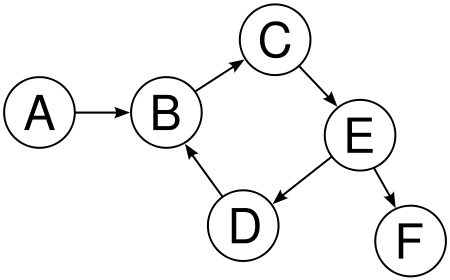
A graph is a data structure that is made up of nodes connected by edges. Each node can have any number of connections, which can be directed (one-way) or undirected (two-way). Graphs are used to represent relationships between data, such as roads on a map or flights between cities. They can also be used for solving problems, such as finding the shortest path between two points.
What to Consider When Picking a Data structure
When picking the right data structure for your database needs, there are a few factors that you should consider:
1. Space Requirements
The amount of space your data structure requires is an important factor to consider when choosing a data structure. Different data structures require different amounts of space to store and manipulate data.
2. Access Speed
The speed at which you can access and manipulate data is an important factor when choosing a data structure. Different data structures have different access speeds, so choosing the one that will provide the best access speed for your needs is important.
3. Complexity
The complexity of the data structure is an important factor to consider when choosing a data structure. Different data structures have different levels of complexity, so choosing the one that will provide the best solution for your needs is important.
For example, if you need to store a collection of names, a linked list would be a good choice because it allows for easy addition, removal, and manipulation of data. In contrast, a hash table would be a more complex data structure that would provide fast lookups but could be more difficult to maintain.
If you are looking for an easy and powerful SQL client and database manager, then you've got to try DbVisualizer. It connects to nearly any database.
Scalability
The ability of the data structure to scale is an important factor to consider when choosing a data structure because it affects how well the data structure can handle large datasets. A data structure that can scale well will be able to efficiently store and process large amounts of data, while a data structure that does not scale well may be limited or inefficient when dealing with large datasets. This is especially important for applications that require fast and reliable operations on large amounts of data.. Different data structures have different levels of scalability, so it is important to choose the one that will provide the best solution for your needs. An example of this is if you are designing a social media application. You could choose to use a linked list for the data structure, but this may not be the best choice because it does not scale well with large amounts of data. A better choice would be to use a hash table or a tree structure, which are both highly scalable solutions. These data structures will be able to handle large amounts of data while providing reliable performance.
Cost
The cost of implementing and maintaining the data structure is an important factor to consider when choosing a data structure. Different data structures have different costs, so it is important to choose the one that will provide the best solution for your needs. For example, a high-cost data structure could be a hash table, which is a complex data structure used for searching. It is high cost because it requires more resources to implement and maintain. A low-cost data structure could be a tree, which is used for sorting and searching for data. It is low cost because it requires fewer resources to implement and maintain.
Implementing Stacks(LIFO) In SQL
Stacks can be implemented using a variety of data structures, such as linked lists, arrays, and heaps. The basic operations of a stack include push, pop, and peek. The push operation adds a new element to the top of the stack. The pop operation removes the top element from the stack. The peek operation returns the top element of the stack without removing it.
In order to implement a stack in any relational database, we will need to create a table to store the stack elements. The table should have at least two columns: one for the element data and one for the order (LIFO) of the elements. The following SQL query creates a table to store the elements of a stack:
1
CREATE TABLE stack ( element VARCHAR(50), order INT );
Once the table is created, we can now add elements to the stack using the `INSERT` query. The order column should be incremented for each element added to the stack so that the last element added is the first one removed.
For example, to add the elements “A”, “B”, and “C” to the stack in that order, the following queries can be used:
1
INSERT INTO stack (element, order) VALUES (‘A’, 1);
2
INSERT INTO stack (element, order) VALUES (‘B’, 2);
3
INSERT INTO stack (element, order) VALUES (‘C’, 3);
To remove an element from the stack, we can use the `DELETE` query. The element to be removed must be identified by its order number. For example, to remove the element “B” from the stack, the following query can be used:
1
DELETE FROM stack WHERE order = 2;
Finally, to view the top element of the stack without removing it, we can use the `SELECT` query. The following query will return the top element of the stack:
1
SELECT * FROM stack ORDER BY order DESC LIMIT 1;
We have just written code to implement an incredibly powerful and versatile data structure - the stack! Our code creates a table to store the data elements of the stack and allows us to push and pop elements, as well as view the top element of the stack without removing it. With this code, we have the ability to store and organize data in a way that allows us to access it quickly and efficiently. This is a great way to keep track of information and can be used in a variety of applications.
Conclusion
It is abundantly evident that effective data structure utilization in a relational database can significantly improve data processing and overall performance.
As a beginner, this article can help you in your data structure learning path. You might not understand everything at first, but you will eventually get the hang of it with time and practice. Feel free to explore other data structures we didn’t cover here and reach out to me on LinkedIn if you have any questions.


