intro
Partitions are a very big part of any database management system, including MySQL. In this blog, we will tell you everything about what they are, how they work, and when should you use them. Have a read!
You’ve heard about partitions, haven’t you? Everyone did – ask any developer or DBA worth their salt what partitions are and how they work and you will hear something like “yeah, partitions are kind of like tables within tables – there is RANGE partitioning, LIST partitioning, HASH and KEY partitioning, people can partition their databases by COLUMNS or elect to use subpartitioning as well.” This statement is very true – databases (not only MySQL) indeed treat partitions as tables within tables – and that’s the whole concept of partitioning!
Partitions are necessary whenever we have a lot of data to work with – many elect to use indexes, but they don’t always cut the chase. Combining indexes with partitions make even the work of biggest search engines a breeze – did you know that one of the biggest data breach search engines in the world – BreachDirectory – is also built on the same principle?
That‘s because partitions let us archive data in a way that‘s applicable to our use case and at the expense of disk space, make search queries a breeze to work with.
Types of Partitions
If you‘re a heavy user of MySQL, you will know a little about the fact that the database management system offers multiple types of partitions to choose from. MySQL offers us the following types of partitions (all of them are horizontal – MySQL doesn’t offer support for vertical partitioning):
As you can see, there are 5 partitioning types and one type referring to subpartitioning as well. Here’s how they all work:
Partitioning by RANGE & LIST
A table partitioned by RANGE refers to a table that’s partitioned by taking into account values that are more than or less than a specified value. Here’s an example:

Any column can be partitioned by RANGE – RANGE partitioning also allows characters as partitioning values, but only those that go up in value (e.g. a to z) can be accepted. Such an approach would do:
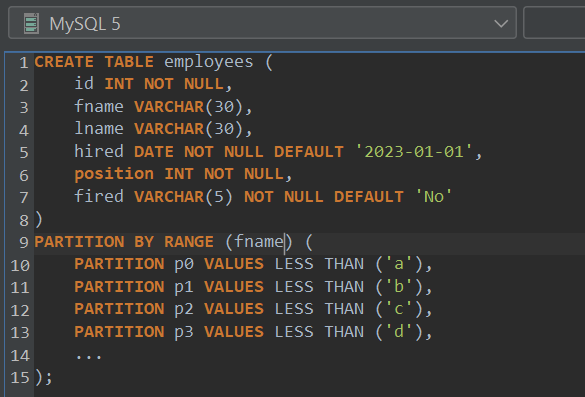
It’s not necessary to have partitions from a to z – if necessary, we can specify 3 or 4 (for example, less than “a”, “g”, “z”) and that will do. It’s always recommended to create a partition for values less than the maximum value (numeric or character) as well.
Partitioning by LIST is similar, it’s just that the user needs to give MySQL a specific list of values. It’s not useful in many cases, but for those needing to partition their data into East, West, Center, and South, for example, it may as well do. Here’s an example:

Partitioning by COLUMNS
Partitioning by COLUMNS is similar to partitioning by RANGE or LIST – in fact, it’s a continuation of these partitioning types. Partitioning by columns can be achieved by partitioning them by range or by list – when partitioning by range is in place, everything looks like so:
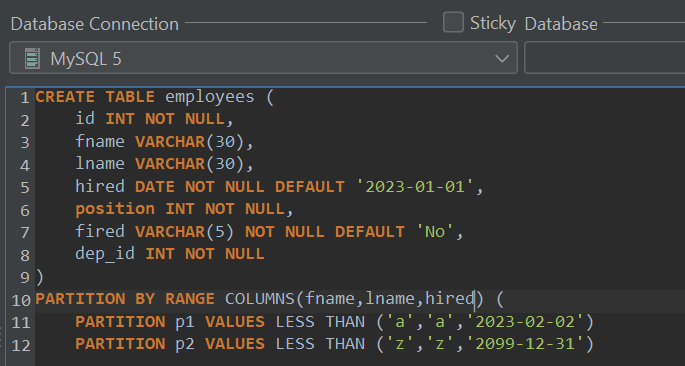
Partitioning by RANGE LIST is the same way, just in place of LESS THAN we’d have IN – in that case, all values would need to be in a specific pre-defined list.
Partitioning by HASH & KEY
Partitioning by HASH is pretty simple – define a number of partitions that your data will be spread across and you have partitioning by HASH:
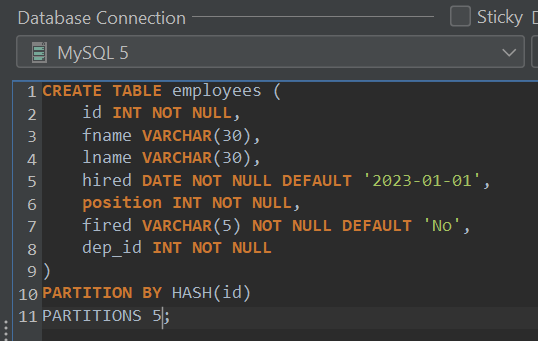
No matter how many partitions would be specified, data will always be distributed across them evenly. Same with partitioning by KEY – specify a partitioning by KEY (you can specify a key if it’s a part of a primary key), then provide a number of partitions you’d want to employ:
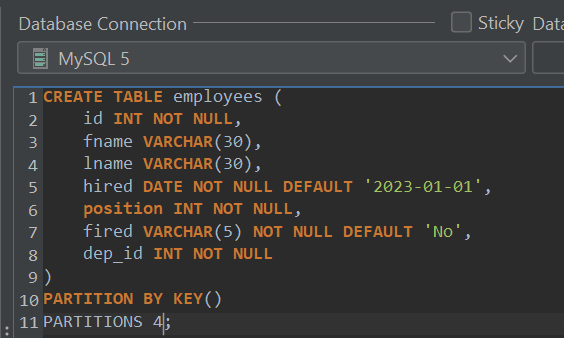
Again, data will be distributed evenly across the specified number of partitions.
Subpartitioning
Subpartitioning is just what it sounds like – it refers to partitions within partitions themselves. To subpartition a partition, make a partition B within the partition A. Keep in mind that when subpartitioning, you can also make use of multiple partitioning types and that’s one of the most frequent use cases of subpartitioning to begin with. Here’s a nice example:
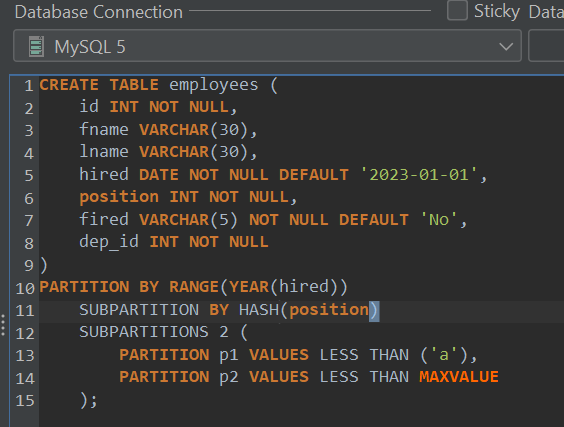
See? We’ve first partitioned the table by RANGE, then subpartitioned it by hash through another column. Such an approach is rarely used, it’s very useful when we aren’t sure if we would make use of a single partitioning type – partitioning by RANGE may not be a fit, but perhaps partitioning something by one type, and something by another type will do? That’s subpartitioning.
Databases Beyond Partitioning & Summary
Although in some cases partitioning may be critical for performance, that’s not always the case. Partitions may be necessary to split data into smaller chunks, but keeping other tips and tricks in mind will certainly come in useful too.
For example, knowing how MySQL uses indexes will certainly be beneficial whether you will use partitions or not – indexes are used to find rows matching a specific WHERE clause if a wildcard doesn’t obstruct the search operation. Indexes also take up space on the disk, but provide us performance benefits in return.
Another way to improve your database performance would be related to the usage of SQL clients. One of such SQL clients is DbVisualizer itself: with over 6 million downloads across the world and some of the world’s most powerful companies using the tool, you can’t go wrong.
If you are looking for an easy and powerful SQL client and database manager, then you've got to try DbVisualizer. It connects to nearly any database.
DbVisualizer will let you visualize your database posture, simplify your queries, allow you to write queries quicker, and it also comes with a wide variety of other benefits like your personal workspace, visual query builder, and others as well – make sure to grab a free trial of the software today, read our blog to learn more about the stance of databases, and until next time!
Frequently Asked Questions
What Are Partitions?
Think of partitions as tables within tables within your database management system of choice – they essentially split your tables into even smaller, manageable chunks of data so that your search queries can become faster.
What Are the Types of Partitioning in MySQL?
MySQL supports partitioning by RANGE, LIST, COLUMNS, HASH, KEY, and subpartitioning.
When to Use Partitions?
Partitions should be used whenever you notice a drop in performance related to your SELECT queries. Indexes, database normalization, and optimizing database settings via my.cnf can nicely supplement partitions too.
Should I Use Subpartitioning? Why?
Subpartitioning might be useful if you want to make use of multiple types of partitioning at once, but otherwise, not so much. If you elect to use subpartitioning, make sure to familiarize yourself with it by having a glance at the MySQL documentation.

