intro
In this guide, we will delve into the concept of the DISTINCT clause in PostgreSQL and explore how it allows you to stamp out duplicate records, enabling you to focus on distinct values across various database tables - let’s get started.
Preface
Have you ever encountered duplicate values in your database as a database developer? These are common problems database developers run into in their lives as developers.
PostgreSQL solves this issue by enabling developers to rule out duplicate values from query results using the PostgreSQL DISTINCT clause. This is significant in ensuring error-free data analysis and reporting.
This article provides a comprehensive guide to the syntax, usage, and performance considerations of using the PostgreSQL DISTINCT clause. We’re going to discuss the importance of using this feature and by the end of this article, readers will have a solid understanding of how to remove duplicate rows from a result set.
What is the PostgreSQL SELECT DISTINCT Clause?
The SELECT DISTINCT clause removes duplicate records in a result set by keeping one row, thus the first row or group of duplicate result sets. Duplicate results are basically values or rows that appear more than once in a result set.
The DISTINCT keyword is used in synchrony with the SELECT statement in many database management systems including PostgreSQL and the syntax is as follows:
1
SELECT
2
DISTINCT column x, column y
3
FROM
4
table_name;
Now, let us analyze the syntax. The columns x and y in the syntax above represent the particular column from which you would want to remove duplicate results. The DISTINCT keyword will then operate on the particular column(s) in question and then filter out the duplicate to produce a result set that will contain a unique combination of values from those columns, in this case, columns x and y.
So in the syntax above, the duplicate values will be evaluated based on the values in columns x and y.
As we have said earlier in this blog, PostgreSQL also removes duplicate results by keeping the first row of each row of duplicates found within the result set and it follows the syntax shown below in DbVisualizer:

Let us analyze the syntax:
According to a rule in Postgres, the expression used in the DISTINCT ON clause (in this case, column1) must also be the leftmost expression in the ORDER BY clause. To rephrase it, it should be listed before any other columns in the ORDER BY clause. Postgres will throw an error if the leftmost expression in the DISTINCT ON clause does not match the leftmost expression in the ORDER BY clause.
This rule ensures that PostgreSQL correctly identifies the distinct rows based on the leftmost expression and orders the rows accordingly. Let us now look at some specific use cases of the DISTINCT clause in PostgreSQL.
The PostgreSQL DISTINCT Clause - Use Cases
Now, we’re going to look into a few use cases that will help us grasp a holistic understanding of this concept but before that, let us make sure the prerequisites are ready. We will need to:
Let us now create a database called ‘closet’ with the command below:
1
CREATE DATABASE closet;
Run the command above in DbVisualizer, navigate to the left pane, and locate the newly created database as shown below:

Next, let us create a table with the command below:

The next thing to do is to insert some data into the created table. We can do this by running the query below in the SQL commander of DbVisualizer:
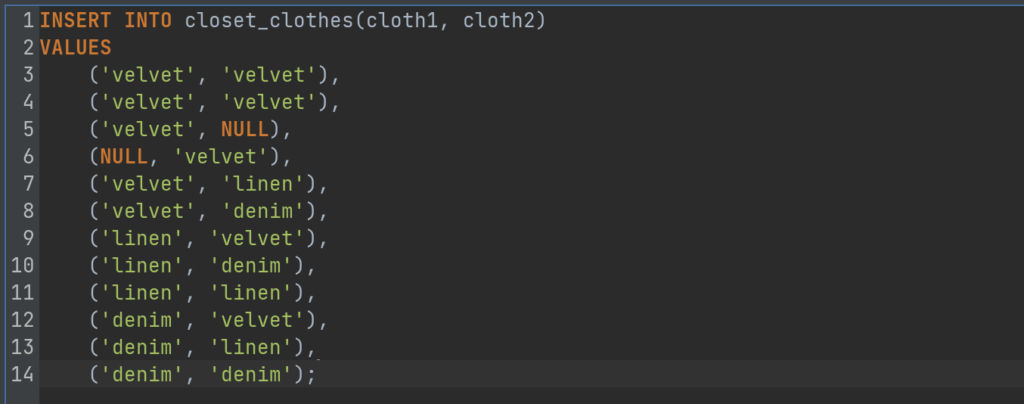
Run the query below in the SQL Commander of DbVisualizer to know whether everything is intact:

Great! We can see from the result set above that everything is intact. Let us look at the use cases in the following examples:
1) Using PostgreSQL SELECT DISTINCT Clause on a Single Column
The SELECT DISTINCT clause can be used on a single column to select unique values from that column and then produce a result set that is arranged alphabetically due to the presence of the ORDER BY clause. Let us look at a typical scenario as shown below:

2) Using the SELECT DISTINCT Clause on Multiple Columns
As we have said earlier in this blog, if we specify two columns, Postgres combines the values within them and produces a result set with a unique combination from the two columns. The same thing happens here: when we specify the two columns cloth1 and cloth2 with the SELECT DISTINCT clause, Postgres will combine the values in both columns to analyze the uniqueness of the rows.
For example, let us build a query that will return a unique combination of cloth1 and cloth2 from the closet_clothes table. Keep in mind that the closet_clothes table has two rows with velvet values in both cloth1 and cloth2. Now, when we apply the DISTINCT to both columns, one row will be removed from the result set because it is clearly a duplicate.

Awesome! We can see that Postgres has combined the values in both columns to analyze the uniqueness of the rows and has produced a result set with no duplicates.
Conclusion
The PostgreSQL DISTINCT keyword is a powerful tool for handling duplicate values in query results. We explored the usage of the SELECT DISTINCT clause on a single column, which allows us to obtain unique values from that column. This is particularly useful when we want to retrieve a list of unique values for filtering, or analysis purposes.
To better appreciate its capabilities, you need a tool that helps you manage databases and visually explore query results. This is where a full-featured database client like DbVisualizer comes in. In addition to being able to connect to several DBMSs, it offers advanced query optimization functionality, and full support for all database features, including DISTINCT. Download DbVisualizer for free now!
FAQs
What is the purpose of the DISTINCT keyword in PostgreSQL?
It is used to retrieve unique values from a column or a combination of columns to return a result set that is free of duplicate values.
How do I use the DISTINCT keyword in a SELECT statement?
Include it immediately after the SELECT keyword in your built query. For example:
1
SELECT DISTINCT column_name FROM table_name;
This will retrieve the unique values from the specified column.
Can I use the DISTINCT keyword with multiple columns?
Yes, you can use the DISTINCT keyword with multiple columns. In such cases, the combination of values from all the specified columns will be considered when evaluating uniqueness.
Does using DISTINCT affect the order of the query results?
No, using the DISTINCT keyword does not affect the order of the query results. It focuses on eliminating duplicate records in a result set. ORDER BY is what is responsible for imposing a specific order.
For example, let us assume that we have a table called developers with the following data:
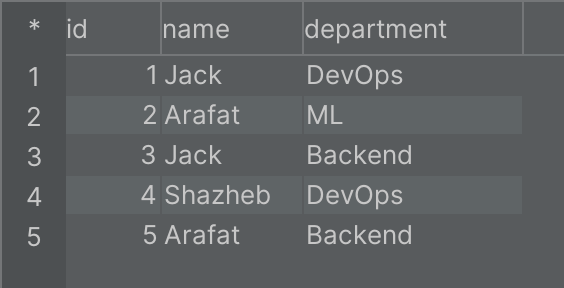
Let’s say, from the table shown above, we want to retrieve a well-defined list of the names of departments from the developers table. To show that the DISTINCT keyword does not affect the order of the query results, let us use the DISTINCT keyword in the SQL statement below:
1
SELECT DISTINCT department from developers;
The result of this query is shown below in DbVisualizer:
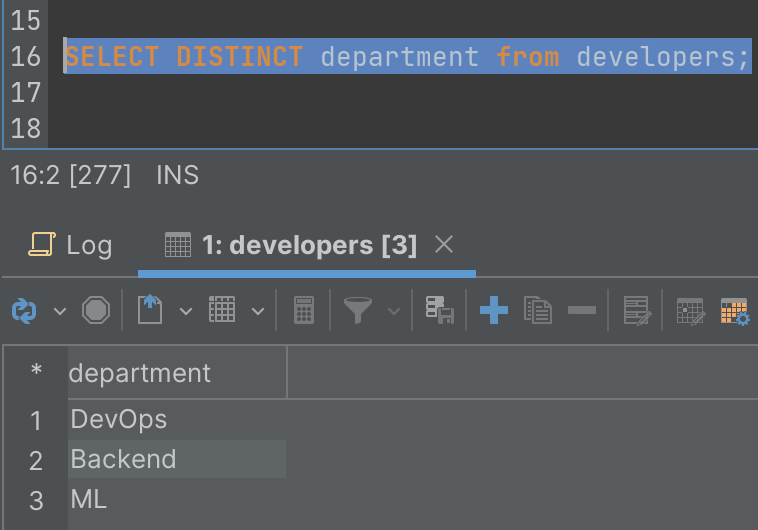
From the query result shown, we can see that the DISTINCT keyword warrants that only different department names are returned in the result, getting rid of duplicates completely.
Please take notice that there is no assurance as to the developers' order in the result set and this can be attributed to the nature of Postgres.
The ORDER BY clause must be used if you want to force a certain order on the query results. For instance, you may change the query to the query below if you want the departments to be listed in ascending order alphabetically:
1
SELECT DISTINCT department FROM developers ORDER BY department ASC;
The updated query result would then be:

Here, the ORDER BY clause has determined the order of the query results.

