intro
Let’s discover and explore how the best databases currently available support agentic RAG scenarios in AI workflows.
Agentic RAG is the natural evolution of traditional RAG scenarios and is quickly becoming one of the newest and hottest trends, driven by its pivotal role in the emerging wave of agentic AI. These workflows improve a lot when the data retrieved by the RAG agent can be stored and reused for future scenarios or integrated into other agentic architectures.
In this article, you will discover the key database requirements to support agentic RAG, as well as the best agentic RAG databases (both vector and non-vector) available today.
Let’s dive in!
What Are the Database Needs for Agentic RAG Scenarios?
Agentic RAG (Retrieval-Augmented Generation) scenarios advance traditional RAG by integrating intelligent AI agents into the data retrieval and response generation process. Unlike static RAG, which simply retrieves documents and generates answers, agentic RAG revolves around AI agents that can reason, plan, and decompose complex queries into smaller tasks.
These agents use various tools to access external knowledge bases. The retrieved information (e.g., raw data like HTML pages) is often converted into embeddings and stored in vector databases.
In vector databases, support for diverse distance metrics (such as cosine and L2) and indexing strategies (like HNSW and IVF) enhances retrieval accuracy and speed. Now, keep in mind that vector databases are not always as established as traditional relational databases. Thus, robust API support and clear documentation are fundamental for smooth integration into evolving agent workflows.
At the same time, some agentic RAG workflows require retaining the original raw data. In this case, you need both semantic (vector) and symbolic (structured) data access. Pure vector databases may fall short here, making hybrid databases a better fit. Here, a “hybrid database” is a kind of database that combines vector search capabilities with traditional data storage (e.g., a relational database with vector extensions).
Regardless of the database choice, low-latency performance is essential, as agents may perform multiple lookups per task. Overall, databases for agentic RAG must balance scalability, precision, and flexibility to meet these demanding needs.
Top Databases for Agentic RAG
Let’s now explore the top databases for agentic RAG scenarios, organized by type (vector, SQL, and NoSQL).
If you are eager to jump ahead, check out the summary table below:
| Database | Type | Data storage approach | Nature | Distance metrics | GitHub stars |
|---|---|---|---|---|---|
| Pinecone | Vector database | Pure Vector | Premium (SaaS solution) | Cosine, Euclidean, Dot Product | — |
| Weaviate | Vector database | Hybrid | Free (open-source) | Cosine, Squared L2, Dot Product, Manhattan, Hamming | 14k+ |
| Milvus | Vector database | Pure Vector | Free (open-source) | L2, Inner Product, Cosine, Jaccard, Hamming, BM25 | 36k+ |
| Qdrant | Vector database | Hybrid | Free (open-source) | Cosine, Euclidean, Dot Product, Manhattan | 24k+ |
| Chroma | Vector database | Pure Vector | Free (open-source) | Cosine, Inner Product, Squared L2 | 21k+ |
| MySQL 9 | Relational database | Hybrid | Free (open-source) | Cosine, Dot Product, Euclidean | — |
PostgreSQL +pgvector | Relational database | Hybrid | Free (open-source) | L2, Inner Product, Cosine, L1, Hamming, Jaccard | 16k+ (pgvector) |
| TimescaleDB | Relational database | Hybrid | Free (open-source) | Cosine, L2, Inner Product, L1, Hamming, Jaccard | 19k+ |
| Oracle 23ai | Relational database | Hybrid | Both free (for developers) and premium (for enterprises) | Euclidean, Squared L2, Cosine, Dot Product, Manhattan, Jaccard, Hamming | — |
| Elasticsearch | Document NoSQL database | Hybrid | Free (open-source) | L1, L2, Cosine, Dot Product | — |
| Neo4j | NoSQL Graph database | Hybrid | Both free (open-source) and premium (for enterprise) | Euclidean, Cosine | 14k+ |
| MongoDB Atlas | Document NoSQL database | Hybrid | Premium (Cloud solution) | Cosine, Dot Product, Euclidean | — |
| AWS Neptune | Graph NoSQL database | Hybrid | Premium (Cloud solution) | Cosine, L2, Squared L2, Dot Product | — |
Note: The databases in each category are presented in random order, not as rankings.
Vector Databases
Explore the list of the most widely used vector databases in agentic RAG scenarios.
Pinecone
Pinecone is a SaaS vector database with features tailored for agentic RAG workflows.
It supports both dense and sparse indexes, with Cosine, Euclidean, and Dot Product distance metrics. Pinecone also enables hybrid search, allowing queries on both a dense and sparse index for better retrieval results.
It can merge and de-duplicate results from multiple indexes, then apply a reranking model to score them based on unified relevance and return the most relevant matches. Learn about it in our article about Pinecone.
Weaviate

Weaviate is an open-source vector search engine and database built for semantic search and AI applications. It enables native vector storage combined with a graph-like data model and schema-based typing.
The distance metrics you can apply are Cosine, Squared L2, Hamming, and Dot Product, Manhattan. Weaviate offers hybrid search combining vector similarity with keyword filtering to power contextualized agent RAG workflows.
Additionally, it supports modular plugins for custom vectorizers and transformers, making it highly extensible. Weaviate counts over 14k stars on GitHub.
Milvus
Milvus is an open-source, highly scalable vector database built for AI applications. More specifically, it is built for enabling workflows involving massive unstructured data.
It provides efficient vector storage and supports both approximate (ANN) and exact nearest neighbor search (ENN). Milvus supports multiple distance metrics: Milvus supports multiple distance metrics, including Euclidean (L2), Inner Product, Cosine Similarity, Jaccard, Hamming, and BM25.
It also empowers hybrid search by combining vector similarity with scalar filtering. Plus, it supports distributed deployments for high availability and scalability. It has over 36k stars on GitHub.
Qdrant
Qdrant is an open-source vector database that supports AI applications with scalable similarity search. It supports dense vector storage with efficient indexing based on HNSW (Hierarchical Navigable Small World) graphs.
Cosine, Euclidean, Dot Product, and Manhattan are the supported distance metrics. Qdrant enables hybrid search with payload filtering, offers real-time updates and transactional consistency, and provides REST/GRPC APIs for easy integration.
It boasts over 24k stars on GitHub.
Chroma
Chroma is an open-source vector database focusing on developer-friendly APIs and integrations for machine learning and AI applications.
It supports native vector storage and is built around embedding-based search and retrieval. Chroma uses an HNSW index that supports distance metrics such as Cosine, Inner Product, and Squared L2.
With over 21k stars on GitHub, Chroma is a valid choice for both rapid prototyping and production-grade agentic RAG pipelines.
Relational Databases
Take a look at the best relational databases suited for agentic RAG scenarios.
MySQL 9
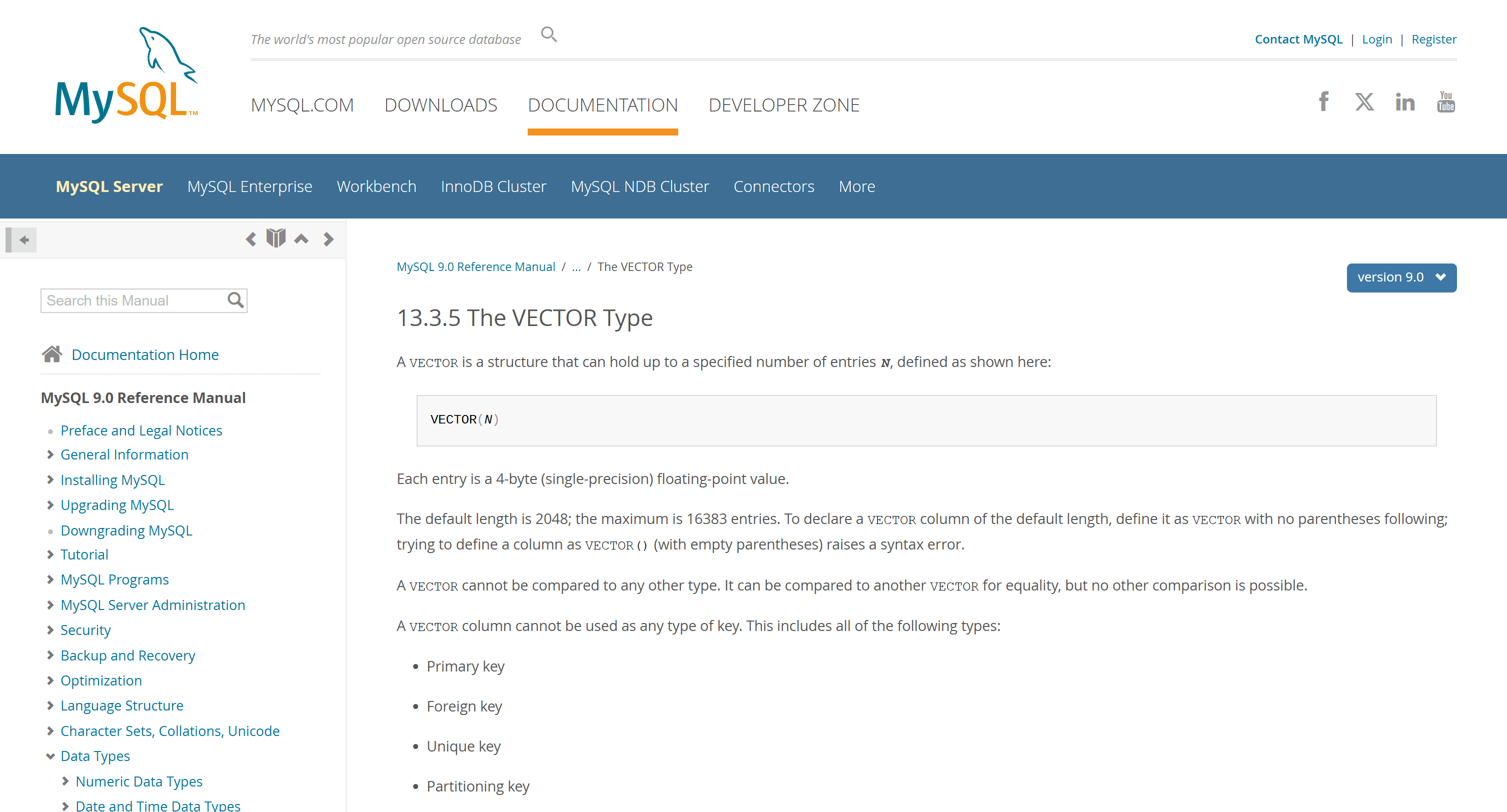
MySQL 9 introduced support for embedding storage through the new VECTOR data type.
In addition to storing vector data, MySQL 9 also enables similarity search by supporting the calculation of the distance between vectors. The distance metrics it supports are Cosine, Dot, and Euclidean.
For more details, read our dedicated article on the MySQL 9 VECTOR data type.
PostgreSQL with pgvector
PostgreSQL does not natively support vector embeddings, but this functionality is made possible through the open-source pgvector extension.
With over 16k stars on GitHub, pgvector extends PostgreSQL with capabilities for AI and similarity search, such as:
Explore what this extension has to offer in our guide on pgvector.
TimescaleDB
TimescaleDB is an open-source PostgreSQL extension that functions as a time-series database built for high-performance real-time analytics. It extends PostgreSQL’s capabilities to efficiently handle time series data, events, real-time analytics, and vector search by building on the pgvector and pgvectorscale.
Currently, the supported similarity distance metrics are Cosine, L2 (Euclidean), Inner Product, L1 (Manhattan), Hamming, and Jaccard. TimescaleDB also supports Streaming DiskANN indexing for efficient approximate nearest neighbor search.
Oracle 13ai
Oracle 23ai, the latest version of Oracle Database, is a scalable relational database with native support for vector storage. In detail, it enables advanced similarity search and agentic RAG workflows directly through SQL.
Its Oracle AI Vector Search features support multiple distance metrics, including Euclidean, Euclidean Squared, Cosine Similarity, Dot Product, Manhattan, Jaccard, and Hamming. It also offers hybrid vector indexes, ONNX-based embeddings, and many other aspects for integration with modern LLMs.
NoSQL
See the top NoSQL databases that support agentic RAG workflows.
Elasticsearch
Elasticsearch is an open-source, distributed, RESTful search engine. It can also be classified as a document-oriented NoSQL database.
Elasticsearch supports vector similarity search through the dense_vector and sparse_vector field types. These make it suitable for semantic search and RAG workflows.
Elasticsearch supports both exact (brute-force) and approximate nearest neighbor (ANN) search using algorithms like HNSW. The supported distance metrics for similarity calculations include L1 (Manhattan), L2 (Euclidean), Cosine Similarity, and Dot Product. It can also perform k-nearest neighbour (kNN) queries.
A key strength for RAG scenarios is Elasticsearch's ability to combine vector search with traditional keyword-based search (BM25) through hybrid scoring.
Neo4j
Neo4j is a graph database that offers integrated support for vector similarity search directly within your knowledge graph structures. In particular, it lets you store embeddings as LIST<FLOAT> or LIST<INTEGER> properties on nodes and relationships.
Neo4j supports approximate nearest neighbor (ANN) search using HNSW indexing for efficient vector retrieval. The primary distance metrics supported are Euclidean and Cosine.
Also, it empowers vector similarity search across connected graph data. That makes it an ideal choice for knowledge graphs and contextual RAG pipelines, especially in GraphRAG scenarios.
MongoDB Atlas
MongoDB Atlas introduced vector search starting from Atlas 6.0.11+, with the Vector Search feature integrated directly into the query engine.
It supports approximate (ANN) and exact (ENN) nearest neighbor search through $vectorSearch queries, with features designed specifically for RAG pipelines. Supported distance metrics include Cosine, Dot Product, and Euclidean.
Notably, the MongoDB team has announced plans to bring full-text search and vector search to the MongoDB Community Edition later in 2025.
AWS Neptune
AWS Neptune is Amazon’s fully managed graph database, recently enhanced with native vector search support to address generative AI use cases. As of this writing, it supports distance metrics including Cosine, L2, Squared L2, and Dot Product.
Neptune enables KNN queries and integrates with Neptune ML, which is built on the DGL (Deep Graph Library). Its strength lies in combining graph traversals with vector search, making it perfect for building intelligent agents grounded in connected knowledge.
Conclusion
In this blog post, we saw some of the best databases available for agentic RAG scenarios at the time of writing. We highlighted their key strengths and summarized their main capabilities.
No matter which database you choose, you will need a reliable tool to visually access and manage your data. That is where a top-rated multi-database client like DbVisualizer comes in.
DbVisualizer supports most of the databases mentioned here and enhances your agentic RAG workflows with advanced data storage, exploration, and management features. Try it for free today!


