intro
UPDATE queries are another necessary component of any database management system – in this blog, we walk you through them. Join us!
UPDATE queries are a necessary part of every application. Everyone needs to update data once in a while – everyone makes mistakes, right?
Update queries are just that – they’re queries that help developers update their data. In this blog we’re walking you through them as well.
Why UPDATE?
In its most basic form, UPDATE queries look something along those lines:

Do note that by default, UPDATE queries must have only the SET clause – however, additional parameters can also be included, these being:
The most likely clause you’re going to encounter is WHERE, followed by the IGNORE clause. The priority clauses are used very rarely and if they’re used, they’re usually used in environments where there are a lot of queries running simultaneously and developers need to update data in chunks.
UPDATE Query From the Inside
Here’s how UPDATE queries look like from the inside (to learn how to profile a query, turn back to the second or first part of these tutorials):

We can see that there are multiple things going on:
With UPDATE queries, everything works in a simple fashion – we must have sufficient permissions, InnoDB will create row-level locks in the process, update the data, and end.
Everything may look relatively simple from the outset, but when we dig into the processes we quickly see that everything’s a little more complex than we could imagine.
Advanced DBAs will know that both indexes and partitions slow DELETE, INSERT, and UPDATE queries down because of the fact that data existing in indexes and partitions need to be updated together with the data itself. That’s not it – UPDATE queries can also update multiple columns at once if we run them by specifying multiple columns like so:
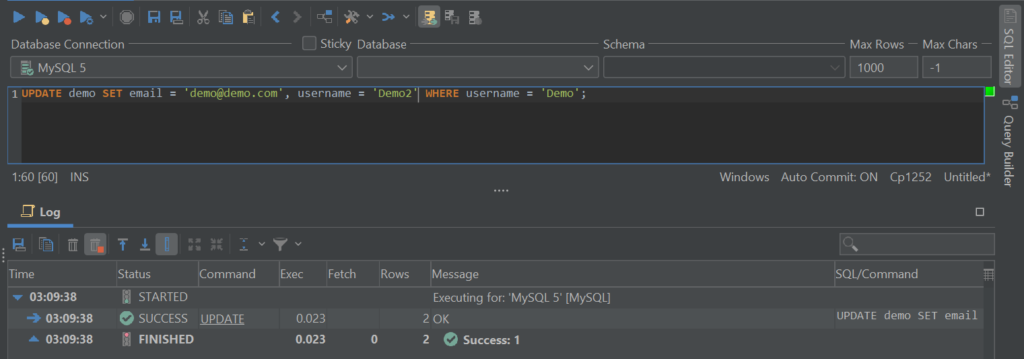
Do note that we specified multiple columns after the “,” sign before the WHERE clause. There’s a downside – when updating a lot of data such queries will definitely take up a lot of time, so there are a couple of other tricks we can pull from our sleeves: the first one is using the IGNORE keyword to ignore all of the errors, but that’s not it either – did you know that the DEFAULT keyword can also be used to update bigger data sets? Yes, that‘s not an usual practice, but the DEFAULT statement can also double as an UPDATE statement in very specific cases:
Now consider the same scenario, just with the DEFAULT keyword in use:


The reason why our DBMS behaved in this way is pretty self-explanatory: some of the fields have already been filled-in prior to inserting the data. We shot two rabbits with one shot: the file was smaller since we didn’t specify other values (think of how much space we could save if there would’ve been billions of records?), and we didn’t have to run an UPDATE query after the LOAD DATA INFILE query – the values were already filled in by the database itself.
Neat, right? Now quick – grab a free trial of DbVisualizer and start being in charge of your database!
Summary
In this blog, we have walked you through the third query in the CRUD acronym – the UPDATE query that’s used to update data within tables. We bet you didn’t know that the DEFAULT keyword can also be used to update data!
Follow us on Twitter, read our blog to stay updated around what’s happening in the database world, and until next time.
FAQs
What Does the UPDATE Query Do? Do Indexes Help it?
The UPDATE query updates data within a table. Indexes and partitions make it slower at the expense of speeding up SELECTs.
What’s the Best Way to Optimize an UPDATE Query?


