intro
TL;DR: Let’s see what you need to know to manage a relational database with billions of rows. 5 lessons learned from dealing with a very large database.
In this article, you will find the top lessons learned from dealing with a database with billions of records. These five lessons will help you understand what tools you should rely on, what to do, and what you to avoid. By the end of this article, you will know how to deal with a billion-row database.
Let's now dig into the five lessons that will help you control a very large database.
Context
I have collaborated with a startup that works in Industry 4.0 for years. Their goal is to develop a fully-featured web application for sports experts, especially to help them explore data and make decisions. Since they are based in Europe - and Europeans love soccer - their target is soccer experts and clubs.
Each soccer game features thousands of events. These include passes, yellow cards, red cards, goals, assists, fouls, corner kicks, saves, throw-ins, and many others. In other words, each soccer game is associated with thousands of records. Considering that hundreds of official soccer games are played every day around the world, you can imagine how large the underlying has become.
Also, this raw data gets analyzed and aggregated by the application, which produces additional new records. Thus, in total, the database stores hundreds of GB of heterogeneous data and contains billions of records. Working for three years in such a scenario helped me understand that you need special measures if you want to manage a billion-record database.
Let’s now see what I learned.
5 Lessons Learned From Managing a Billion-Record Database
A database with billions of records requires special treatment. And here, you will find the list of the five most important lessons you should apply when dealing with such a large database. Note that these lessons apply to any RDBMS technology on the market.
1. Forget About JOINs
Your billion-record database is likely to have several tables with many millions of rows. If you have ever dealt with such large tables, you should know that executing JOIN queries can lead to performance issues. You can perform SELECT queries with simple WHERE conditions in a reasonable amount of time, even in a few milliseconds. But you cannot expect JOIN queries to run in less than a few seconds.

If you do not have the right index and do not apply sufficiently restrictive WHERE conditions, a JOIN query on very large tables may take up to several minutes. In this scenario, you can simply forget about JOINs. Instead, you should try to aggregate data into new tables, duplicate or propagate columns with triggers, or use JSON columns to store aggregated data directly on each row.
2. Be Careful With Indexes
Indexes allow speeding up SELECT queries. At the same time, keep in mind that indexes are most effective on optimized databases. This is especially true when it comes to big data. So, if you want to build a search engine querying such a large database, you need to optimize your database - for example, through normalization.
Also, do not forget that whenever you create an index, optimized data structures are saved to the disk. In other terms, indexes take up disk space. When dealing with small tables, this space can simply be ignored. However, this is not the case when it comes to million-row tables.
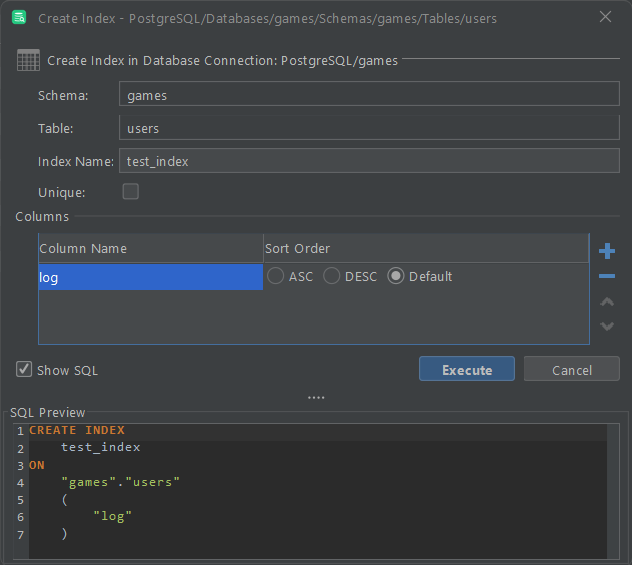
In large tables, advanced indexes on several columns may end up occupying several GB of disk. Since storage comes with a cost, this side effect should be taken into account. This is also why you should periodically drop indexes that you do not use or need. Plus, defining an index on a million-row table can take minutes. Therefore, when dealing with a database with billions of rows, you should not create indexes too lightheartedly.
3. Do Not Rely on Backups
When an UPDATE or DELETE query goes wrong, it can be a serious problem for your business. Data is money, and losing or degrading the quality of your data means losing money. For this reason, you should always perform data backups. After all, data recovery is one of the most important aspects of disaster recovery. This is also why most popular database providers offer data recovery features.
At the same time, restoring data from a backup takes time. With small databases, this generally takes up to a few minutes. On the contrary, with billion-record databases, it usually takes up to a few days. If your business can survive a few minutes of downtime, it is unlikely that it make it through a few days offline or with degraded services. Thus, with a database with billions of rows, you should not rely too heavily on backups. Instead, you have to pay close attention to every write query you launch and need to know what you are doing.
Also, you should look for different ways to back up and restore data. Relying solely on the most common backup techniques or what your database provider offers you may not be the best approach. For example, the MySQL’s LOAD DATA INFILE statement allows you to read rows from a text file into a table at a very high speed. So, you should also consider exporting table data to simple text files as backups.
4. Optimize Your Queries
Spending time writing optimized query when dealing with small databases is not too important. Instead, when working with a billion-row database, it becomes essential. A poorly written query can take several seconds or even minutes. This may result in unacceptable performance for end users.
Also, considering that you should create indexes sparingly when dealing with such a large database, you must be sure to be taking advantage of them. You cannot simply write the first query to extract the data you want that comes to your mind. You need to know what the query will do, why, and what indexes will be used as a result.
If you are looking for an easy and powerful SQL client and database manager, then you've got to try DbVisualizer. It connects to nearly any database.
DbVisualizer allows you to analyze how a query is executed by the database through the Explore Plan feature. In detail, DbVisualizer performs your query and records the plan that the database followed to run it. Through this plan, you can find out whether a specific index is used or not and much more. Learn more about DbVisualizer's Explore Plan feature.
5. Adopt a Reliable Client
To manage a database with billions of rows, you need a fully-featured, fast, advanced client. Most importantly, your client should be reliable. You need to distinguish from a problem with your data, and a bug in your client. In a data-driven company, this is not acceptable.
For example, phpMyAdmin would crash several times and freeze because it is not a good client for such large databases. Also, your database client would offer you whatever you need to deal with such a large database efficiently and effectively. These include query optimization, index definition, ER diagrams, and more. DbVisualizer comes with all these features and many others and is so reliable that even NASA uses it.
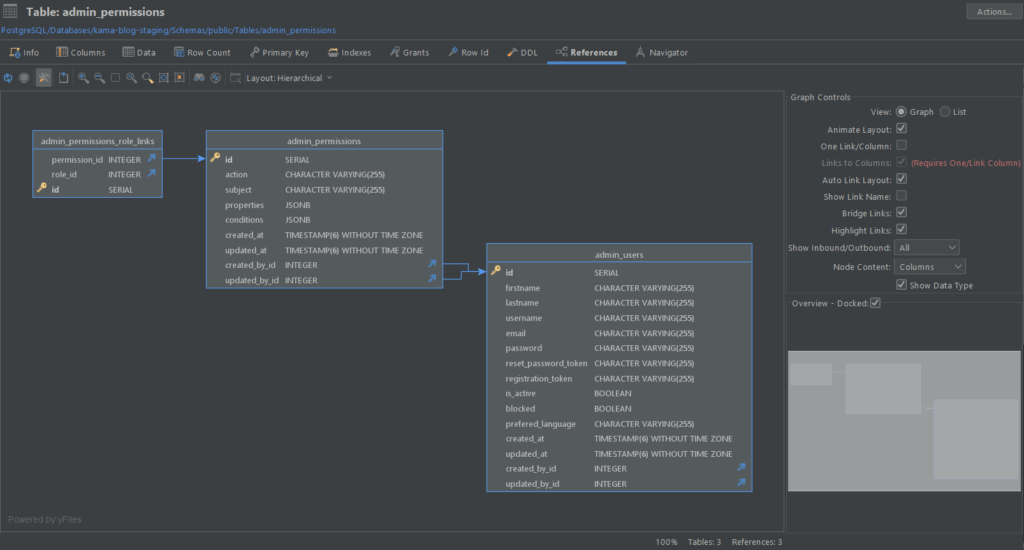
Conclusion
Working with a billion-row database is not easy. At the same time, considering how important data has become, this is something that every software engineer and data scientist should be able to deal with. Here, you had the opportunity to see insightful lessons to learn how to deal with a database with billions of records.
One of the of most important lessons is adopting a reliable database, and DbVisualizer is a top-rated and highly-recommended database client. This is why even NASA opted for it. Download DbVisualizer for free and find out what it has to offer!
Thanks for reading! We hope that you found this article helpful.

