intro
Time to look at what the SQL PIVOT clause is and how it is used in changing one table-valued expression into another — let’s get right into it.
SQL PIVOT table is a relational operator to create a different view of your data. It also provides the opportunity to create pivot tables and to break down data components into different columns and rows for easy analysis.
This blog will guide you through the process of using the PIVOT SQL operator, including its use cases using a tool like DbVisualizer.
Let’s get started!
What Is PIVOT in SQL?
In SQL, pivoting means rotating data from rows to columns to transform and restructure the dataset. That is the contrary of operators like GROUP BY, where data is often summarized into a single dimension.
Generally, there are two types of pivot tables in SQL:
Time to look at how PIVOT table in SQL works across some database management systems. Note that MySQL and PostgreSQL do not directly support SQL PIVOT table, but do have alternative ways of creating pivot tables. Oracle and SQL Server on the other hand do support pivot tables.
How to Use PIVOT Table in SQL
Implementing PIVOT tables in SQL varies across database management systems (DBMSs) as SQL does not have a universal or standard PIVOT syntax. Each DBMS has its way of creating a pivot table. It is worth noting that the logical structure of a pivot table can be broken into three main parts:
The syntax for the SQL PIVOT operator, which is shown below, has three main parts:
Here is the complete structure:
1
-- select the non-pivoted column and the pivoted columns with aliases
2
SELECT
3
[non-pivoted column],
4
[first pivoted column] AS [column name],
5
[second pivoted column] AS [column name],
6
...
7
FROM
8
(
9
-- subquery to select the necessary columns from the source table
10
SELECT [columns]
11
FROM [source_table]
12
) AS source_table
13
PIVOT
14
(
15
-- pivot operation to aggregate data and transform rows into columns
16
[aggregate_function]([pivot_column])
17
FOR [pivot_column] IN ([first pivoted column], [second pivoted column], ...)
18
) AS pivot_table; -- Alias for the result of the pivot operation
Breaking down the syntax:
PIVOT in SQL Server
SQL Server has complete support for the PIVOT operator.
In this example, we will use the PIVOT operator to transform rows into columns and summarize data using aggregate functions like SUM(). Subsequently, we are going to employ also, SQL clauses, such as WHERE, GROUP BY, and ORDER BY for refined data manipulation using this table:
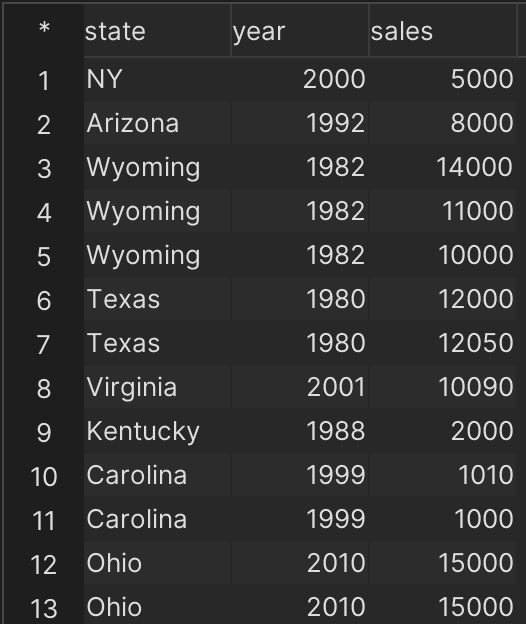
This scenario illustrates how to use the PIVOT operator to filter data for the year 2020 or later (WHERE), group data by city and year (GROUP BY), and sort the data by city (ORDER BY):
1
-- select the state and sales data for the years 1980, 1982,.... 2010
2
SELECT
3
state,
4
[1980] AS Sales_1980,
5
[1982] AS Sales_1982,
6
[1988] AS Sales_1988,
7
[1992] AS Sales_1992,
8
[1999] AS Sales_1999,
9
[2000] AS Sales_2000,
10
[2001] AS Sales_2001,
11
[2010] AS Sales_2010,
12
13
FROM
14
(
15
-- subquery to select state, year, and sales from the state_sales table
16
SELECT state, year, sales
17
FROM states
18
WHERE year >= 2001 -- filtering
19
GROUP BY state, year, sales -- grouping
20
) AS src
21
PIVOT
22
(
23
-- pivot the sales data to have years as columns, averaging the sales over each year
24
SUM(sales) -- aggregating
25
FOR year IN ([1980], [1982], [1988],[1992],[1999],[2000],[2001],[2010])
26
) AS pvt;
Execute the query, and you will get the following result:

PIVOT In Oracle
Similar to SQL Server, Oracle also supports the PIVOT operator to transform rows into columns. However, the syntax of the PIVOT operator in the Oracle database differs slightly from that in SQL Server. The query below shows how the PIVOT operator appears in Oracle. Note that the columns are aliased within the PIVOT operator, unlike the outer SELECT statement in SQL Server.
1
-- outer SELECT to choose all columns resulting from the PIVOT operation
2
SELECT *
3
FROM (
4
-- inner SELECT to retrieve the raw data of state, year, and sales
5
SELECT state, year, sales
6
FROM sales
7
)
8
-- PIVOT operation to convert rows to columns
9
PIVOT (
10
SUM(sales)
11
-- specify the year values to pivot and alias them as Sales_<year>
12
FOR year IN (1980 AS Sales_1980, 1982 AS Sales_1982, 1988 AS Sales_1988, 1992 AS Sales_1992, 1999 AS Sales_1999, 2000 AS Sales_2000, 2001 AS Sales_2001, 2010 AS Sales_2010)
13
)
14
ORDER BY state;
Creating Pivot Tables in DBMSs Without Native Support
The PostgreSQL database also does not support the SQL PIVOT operator. Therefore, when creating pivot tables, it is important to use the CASE statement with conditional aggregation. The query below is an example of the conditional CASE statements used to create pivot tables in PostgreSQL.
1
-- Select the state and sum the sales data for the years .....
2
SELECT
3
state,
4
SUM(CASE WHEN year = 1980 THEN sales ELSE 0 END) AS Sales_1980,
5
SUM(CASE WHEN year = 1982 THEN sales ELSE 0 END) AS Sales_1982,
6
SUM(CASE WHEN year = 1988 THEN sales ELSE 0 END) AS Sales_1988,
7
SUM(CASE WHEN year = 1992 THEN sales ELSE 0 END) AS Sales_1992,
8
SUM(CASE WHEN year = 1999 THEN sales ELSE 0 END) AS Sales_1999,
9
SUM(CASE WHEN year = 2000 THEN sales ELSE 0 END) AS Sales_2000,
10
SUM(CASE WHEN year = 2001 THEN sales ELSE 0 END) AS Sales_2001,
11
SUM(CASE WHEN year = 2010 THEN sales ELSE 0 END) AS Sales_2010
12
FROM
13
states
14
GROUP BY
15
state;
16
ORDER BY
17
state;
Run the query in DbVisualizer, and you will get:

Breaking down the code above:
Dynamic Pivoting In SQL
In SQL pivoting, dynamic pivot tables provide compliance by generating columns based on data values. This technique is especially valuable when we have unknown or variable columns. Let’s look at how dynamic pivoting works in SQL Server using dynamic SQL:
1
-- block declaration to execute PL/pgSQL code in an anonymous code block
2
DO
3
$$
4
DECLARE
5
cols text; -- variable to store the list of columns for the dynamic query
6
query text; -- variable to store the dynamic SQL query
7
BEGIN
8
-- get distinct years and construct the list of SUM(CASE...) statements
9
SELECT STRING_AGG(DISTINCT 'SUM(CASE WHEN year = ' || year || ' THEN sales ELSE 0 END) AS "Sales_' || year || '"', ', ')
10
INTO cols
11
FROM states;
12
13
-- construct the dynamic PIVOT query
14
query := 'SELECT state, ' || cols || ' FROM states GROUP BY state ORDER BY state';
15
16
-- execute the dynamic PIVOT query
17
EXECUTE query;
18
END
19
$$;
Breaking down this code:
Not only can dynamic pivoting be done in PostgreSQL, it can also be done in other DBMSs such as Oracle, MySQL, etc. Feel free to learn how to implement dynamic pivoting in these other database management systems.
It’s a wrap!
Conclusion
Pivot tables are essential for converting raw data into structured, insightful views, especially when summarizing or aggregating information for analysis. While some DBMSs like SQL Server or Oracle provide built-in PIVOT operators, others, such as MySQL, require manual workarounds using CASE statements and aggregate functions. These methods are flexible but can lead to lengthy and complex queries, especially as datasets grow.
If you're working with MySQL or any DBMS without native pivot support, a tool like DbVisualizer can make your life easier. With just a few clicks, you can format, organise, and manage even the most intricate SQL queries. DbVisualizer’s user-friendly interface ensures your long and nested pivot queries remain readable and maintainable, saving you time and reducing errors.
Before closing, follow our blog for more updates, and we’ll see you in the next one.
FAQ
What is a Pivot table in SQL and why would I use one?
A pivot table is a data summarization tool that allows you to transform and reorganize rows into columns based on certain criteria. In SQL, pivot tables help summarize and analyze data across multiple dimensions, like summarizing sales by region and month.
What is the difference between PIVOT and UNPIVOT in SQL?
PIVOT converts rows into columns and is commonly used to summarize and aggregate data in a tabular format, where unique values in a row are turned into new column headers. UNPIVOT, on the other hand, converts columns into rows. So basically, it is the reverse of a PIVOT operation and is used to normalize or restructure data into a simpler row-based format.
Does PostgreSQL have a built-in PIVOT function?
No, PostgreSQL doesn’t have a direct PIVOT function like SQL Server. However, you can achieve pivoting in PostgreSQL using CASE statements or the crosstab() function from the tablefunc extension, which allows you to transform row-based data into a pivoted table format.
Does MySQL have a built-in PIVOT function like other databases?
No, MySQL does not have a built-in PIVOT function like SQL Server or Oracle. However, you can achieve the same pivot functionality by combining CASE statements, aggregate functions, and sometimes dynamic SQL.


