intro
Let’s dive into the world of clustered indexes and explore how to optimize a clustered index scan for faster queries.
If you ever worked with databases, you know that indexes speed up queries by allowing the database to avoid scanning the entire table. This is one of the benefits of non-clustered indexes. But what about clustered index scans? In this guide, you will learn everything you need to know to optimize a clustered index scan in SQL!
What Does "Clustered Index Scan" Mean?
In databases that support clustered indexes, a Clustered Index Scan occurs when the database engine needs to read all rows in a table to satisfy a query.
An SQL clustered index organizes the table's data on the disk in a structured and sequential order based on the indexed column—typically the primary key. This design means that the data rows themselves are stored as part of the clustered index.
Essentially, your database considers the clustered index and your table its helping to be the same entity on the disk. That happens because the clustered index can only have one structure, and that structure happens to be the same as your table structure. For more information, take a look at the SQL Server documentation or an answer to the question why you cannot have multiple clustered indexes on the same table on SQLServerCentral, which explains this concept in detail.
Since the clustered index is optimized and ordered based on the indexed column which is usually the primary key, queries that act on non-indexed columns or perform broad scans (e.g. broad searches without specific WHERE clauses) require the database to scan the entire index. These operations involve scanning the physical table on the disk and thus, necessitate an index scan.
Occasionally, a clustered index scan is mistaken for a Full Table Scan, however, they are different as full table scans also cover tables without a clustered index, whereas clustered index scans only apply to tables where the clustered index organizes the data.
Scenarios That Trigger a Clustered Index Scan
The most common scenarios where a clustered index scan is triggered include:
Optimize Clustered Index Scan: Step-by-Step Approach
As you likely gathered, a clustered index scan ensures correctness by retrieving all rows that match the specified conditions. On the other hand, it can significantly degrade query performance, especially for large tables. This is why understanding how to optimize a clustered index scan is so important!
Unfortunately, there is not a one-size-fits-all solution. The ultimate goal is to adjust or refine clustered indexes and optimize query filters to encourage an index seek. An index seek allows the database engine to retrieve only the relevant rows, avoiding the need to scan the entire table.
Let’s now explore an example of clustered index scan optimization using SQL Server and DbVisualizer, a highly rated, multi-database, and powerful database client.
Step #1: Prerequisites
Suppose you have a Sales table that records the total amount of daily sales. In other words, each row represents a specific day, along with the overall quantity of sales made on that day.
Here is the SQL DDL for the Sales table:
1
CREATE TABLE
2
Sales
3
(
4
Id INT NOT NULL IDENTITY,
5
SaleDate DATE NOT NULL,
6
Quantity INT NOT NULL,
7
PRIMARY KEY (Id)
8
);

Thanks to DbVisualizer, you can easily access the DDL of any table by clicking on the “DDL” tab in the interface.
In this example, Id is defined as a PRIMARY KEY. So, SQL Server automatically creates a clustered index on the column. To verify that, you can execute the following query:
1
EXEC sp_helpindex 'Sales';
The sp_helpindex stored procedure in SQL Server provides detailed information about the indexes defined on a table.
The result will look something like this:

Note how the Sales table has a clustered index called PK__Sales__3214EC07DEBFE079.
Step #2: Perform a Range Query
Assume the Sales table is always queried by date ranges, such as fetching data from a starting date A to an ending date B. The generic query for this operation would look as in this example:
1
SELECT *
2
FROM Sales
3
WHERE SaleDate BETWEEN '2025-02-04' AND '2025-02-10';
The above query retrieves data for all rows where the SaleDate is between 2025-02-04 and 2025-02-10.
To check whether this query performs a clustered index scan or not, you can execute it in DbVisualizer's Explain Plan mode:
Explain Plan is a feature that helps you analyze how a query will be processed by the database, such as determining whether an index will be utilized or if a full table scan will occur. This is an option available in multiple database management systems, as you can learn in our SQL EXPLAIN article. The result will look like this:
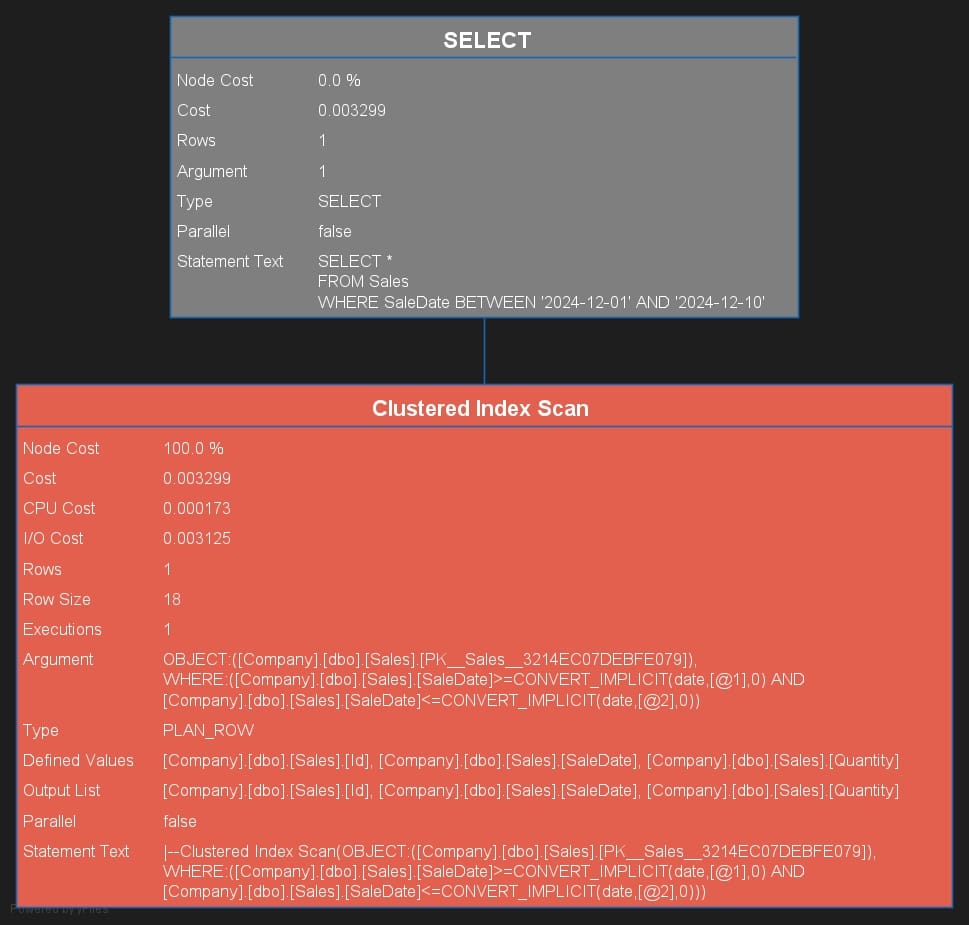
Here, you can clearly see that the query performs a clustered index scan as expected. This is because the query filters rows based on a range of SaleDate values, which is a column included in the clustered index.
Step #3: Replace the Clustered Index
Since the queries on Sales are all targeting the SaleDate column, it makes sense to drop the current clustered index and replace it with a new one on SaleDate, which is seen as the real primary key.
To remove the existing clustered index, drop the primary key constraint on Id (the name of the constraint is PK__Sales__3214EC07DEBFE079):
1
ALTER TABLE Sales DROP CONSTRAINT PK__Sales__3214EC07DEBFE079
Then, move the primary index to SaleDate:
1
ALTER TABLE Sales ADD CONSTRAINT PK_Sales_SaleDate PRIMARY KEY (SaleDate);
This will automatically create a clustered index called PK_Sales_SalesDate on Sales.
After creating the new index, run sp_helpindex again to verify the changes:
1
EXEC sp_helpindex 'Sales';
This time, you will get:

The clustered index is now on the column SalesDate.
Step #4: Perform the Range Query Again
Run the test query once more in Explain Plan mode in DbVisualizer:
1
SELECT *
2
FROM Sales
3
WHERE SaleDate BETWEEN '2024-12-01' AND '2024-12-10';
This time, you should see that the query performs a clustered index seek instead of a clustered index scan:

Notice how the overall query cost decreases slightly. The improvement appears minimal because the Sales table currently contains only 15 rows of sample data. At the same time, the performance gains would be far more significant in real-world scenarios with larger datasets.
Et voilà! You’ve just learned how to optimize a clustered index scan.
Conclusion
In this blog post, you learned about how to optimize a clustered index scan, especially in a complete example in SQL Server. As discussed, the process becomes much easier with the Explain Plan mode from DbVisualizer.
DbVisualizer also offers many other features, such as visual query execution, data exploration, and table discovery. Additionally, it includes advanced features like SQL formatting and ERD-like schema generation. Try DbVisualizer for free today!
FAQ
What is the difference between a clustered index scan and a full table scan?
A clustered index scan reads the data in the order defined by the clustered index. On the other hand, a full table scan reads the entire table, even if it does not have any indexes defined on any columns.
What is the difference between a clustered index scan and an index seek?
A clustered index scan reads all rows from the table in the order defined by the clustered index, while an index seek looks up specific rows directly using an index, which is faster for precise queries.
What is the difference between a clustered index scan and a non-clustered index scan?
A clustered index scan accesses data in the order defined by the index while a non-clustered index scan uses a separate structure to look up values and then retrieves corresponding data.
Why use a database client when dealing with indexes?
DbVisualizer is a robust, highly-rated multi-database client that lets you manage various databases from one platform. One of its standout features is the ability to visually create indexes, eliminating the need to memorize specific syntax for creating clustered or non-clustered indexes across different databases. This simplifies database management and makes it more user-friendly for individuals at any skill level. Grab a 21-day DbVisualizer free trial!
Where can I learn more about how to optimize a clustered index scan?
You can learn more by exploring SQL optimization books, online tutorials, database documentation, and specialized forums like Stack Overflow or our guide on working with SQL query optimization.


