intro
This guide will teach you how to leverage PostgreSQL indexes to improve query performance and explore the different types of indexes available.
Slow database queries can cripple application performance and frustrate users. A simple product search that takes 10 seconds instead of milliseconds can drive customers away from your e-commerce site. The PostgreSQL index mechanism is the solution to this problem, acting as a shortcut that helps the database find data quickly without scanning entire tables.
Let’s learn more about Postgres indexes!
Introduction to PostgreSQL Indexes
Time to start exploring the world of indexing in PostgreSQL.
How Indexes Work
When you execute a query without indexes, PostgreSQL performs a sequential scan, examining every row in the table. This approach works fine for small tables but becomes painfully slow as data grows.
SQL indexes create a separate, organized structure that points to the actual table rows, enabling PostgreSQL to find data in logarithmic time rather than linear time.
This is how the index lookup process works:
When PostgreSQL Indexes Make the Biggest Impact
Indexes provide the most dramatic performance improvements in these scenarios:
Creating Your First PostgreSQL Index
Let's walk through a practical example using "QuickShop," an online retailer experiencing slow product searches.
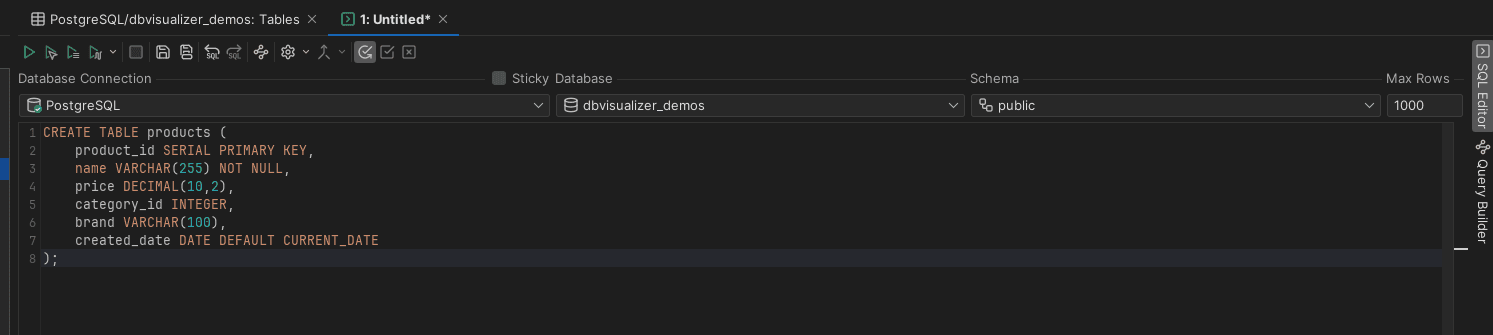
In the following example, we’ll assume that QuickShop has a products table with 100,000 items. Customer searches for "wireless headphones" are taking 5-8 seconds, causing users to abandon their shopping sessions. Here's their table structure:
1
CREATE TABLE products (
2
product_id SERIAL PRIMARY KEY,
3
name VARCHAR(255) NOT NULL,
4
price DECIMAL(10,2),
5
category_id INTEGER,
6
brand VARCHAR(100),
7
created_date DATE DEFAULT CURRENT_DATE
8
);
Step 1: Populate the Table with Test Data
Now we'll add 100,000 sample products to simulate QuickShop's inventory with the following query:
1
INSERT INTO products (name, price, category_id, brand)
2
SELECT
3
CASE (generate_series % 10)
4
WHEN 0 THEN 'Wireless Headphones Model ' || generate_series
5
WHEN 1 THEN 'Bluetooth Speaker Pro ' || generate_series
6
WHEN 2 THEN 'Gaming Mouse Elite ' || generate_series
7
WHEN 3 THEN 'Mechanical Keyboard ' || generate_series
8
WHEN 4 THEN 'Smartphone Case ' || generate_series
9
WHEN 5 THEN 'Laptop Stand ' || generate_series
10
WHEN 6 THEN 'USB Cable ' || generate_series
11
WHEN 7 THEN 'Power Bank ' || generate_series
12
WHEN 8 THEN 'Tablet Screen Protector ' || generate_series
13
ELSE 'Smart Watch Band ' || generate_series
14
END as name,
15
(random() * 500 + 10)::DECIMAL(10,2) as price, -- Prices between $10-$510
16
(generate_series % 20) + 1 as category_id, -- 20 different categories
17
CASE (generate_series % 5)
18
WHEN 0 THEN 'Apple'
19
WHEN 1 THEN 'Samsung'
20
WHEN 2 THEN 'Sony'
21
WHEN 3 THEN 'Microsoft'
22
ELSE 'Generic'
23
END as brand
24
FROM generate_series(1, 100000);
The above SQL query inserts 100,000 synthetic product records into the products table by generating a variety of product names, prices, categories, and brands using generate_series(), SQL CASE statements, and random() to simulate realistic and diverse data.
Execute the query in a PostgreSQL database client like DbVisualizer:

Step 2: Measure Current Performance
First, let's see how the query performs without indexes using an SQL EXPLAIN query:
1
EXPLAIN (ANALYZE, BUFFERS)
2
SELECT product_id, name, price, brand
3
FROM products
4
WHERE name ILIKE '%wireless headphones%'
5
AND price BETWEEN 50 AND 300
6
ORDER BY price
7
LIMIT 20;
As you can see, the query took 36.900 milliseconds:

Note that DbVisualizer Pro comes with the “Explain plans” feature. This gives you a visual explain plan with all the info you need to help guide you in writing more efficient queries. See this feature in action in a real-world scenario.
Step 3: Create Strategic Indexes
Now we'll create targeted indexes to solve the performance problem:
1
-- Index for price range queries
2
CREATE INDEX idx_products_price ON products (price);
3
4
-- Index for text searches on product names
5
CREATE INDEX idx_products_name_text ON products USING GIN (to_tsvector('english', name));
6
7
-- Composite index for price and category filtering
8
CREATE INDEX idx_products_category_price ON products (category_id, price);
These have been devised specifically to optimize the previous query. If you aren’t familiar with the above syntax, read our guide on the SQL CREATE INDEX statement.
Launch the query to define the three indexes:

Step 4: Verify the Performance Improvement
After creating indexes, let's test the same query again:
1
-- Update table statistics so PostgreSQL knows about our new indexes
2
ANALYZE products;
3
4
-- Re-run the same query
5
EXPLAIN (ANALYZE, BUFFERS)
6
SELECT product_id, name, price, brand
7
FROM products
8
WHERE name ILIKE '%wireless headphones%'
9
AND price BETWEEN 50 AND 300
10
ORDER BY price
11
LIMIT 20;
This time, the execution time is 1.209 milliseconds.

Compared to before, the query now executes 30 times faster, with dramatically reduced planning overhead. Customer searches that previously took ~37 milliseconds now complete in ~1 milliseconds.
Essential PostgreSQL Index Types
Explore the main PostgreSQL index types.
B-tree Indexes: The Default Choice
B-tree indexes handle most common scenarios and are PostgreSQL's default index type. They're perfect for:
Equality searches:
1
SELECT * FROM customers WHERE email = 'rosie@example.com';
Range queries:
1
SELECT * FROM orders WHERE order_date >= '2024-01-01' AND order_date < '2024-02-01';
Sorting operations:
1
SELECT * FROM products ORDER BY price LIMIT 10;
Creating a B-tree index:
1
-- Single column index
2
CREATE INDEX idx_customers_email ON customers (email);
3
4
-- Multi-column index (column order matters!)
5
CREATE INDEX idx_orders_customer_date ON orders (customer_id, order_date);
GIN Indexes: For Text Search and Arrays
PostgreSQL GIN indexes excel at searching within complex data types like text documents and arrays.
Full-text search example:
1
-- Create a GIN index for text search
2
CREATE INDEX idx_articles_content_search
3
ON articles USING GIN (to_tsvector('english', title || ' ' || content));
4
5
-- Fast text search query
6
SELECT article_id, title
7
FROM articles
8
WHERE to_tsvector('english', title || ' ' || content) @@ to_tsquery('postgresql & performance');
Array search example:
1
-- Create a GIN index for array searches
2
CREATE INDEX idx_products_tags ON products USING GIN (tags);
3
4
-- Find products with specific tags
5
SELECT product_id, name
6
FROM products
7
WHERE tags @> ARRAY['electronics', 'smartphone'];
Partial Indexes: For Filtered Data
Partial indexes only include rows that meet specific conditions, making them smaller and faster for targeted queries.
1
-- Index only active products
2
CREATE INDEX idx_products_active_price
3
ON products (price)
4
WHERE status = 'active';
5
6
-- Index recent orders only
7
CREATE INDEX idx_orders_recent
8
ON orders (customer_id, order_date)
9
WHERE order_date >= CURRENT_DATE - INTERVAL '1 year';
Viewing PostgreSQL Indexes in DbVisualizer
DbVisualizer provides both visual and SQL-based approaches to viewing and managing PostgreSQL indexes.
Visual Index Management

Viewing already established indexes
Creating Indexes Through the GUI

Note: You can also write and execute the query in SQL commander of DbVisualizer like we did in step 2.
Best Practices for PostgreSQL Indexes
Below are some of the best practices to take into consideration when dealing with PostgreSQL indexes:
Conclusion
If there's one thing you should take away from this guide, it should be this: PostgreSQL indexes can make or break your application's performance. I've seen too many projects struggle with user complaints about slow loading times, only to discover that a few well-placed indexes could solve 90% of their problems. The QuickShop example we walked through isn't just theoretical, it represents real scenarios I encounter regularly in production environments. When you can transform an 8-second product search into a 25-millisecond response, you're not just improving technical metrics; you're directly impacting user experience and business outcomes.
Don't try to implement everything at once. Start with your slowest, most frequent queries. Use EXPLAIN ANALYZE to understand what's happening, create targeted indexes, and measure the results. You'll be amazed at how dramatic the improvements can be with relatively simple changes.
Fire up DbVisualizer, happy querying, and we’ll see you next week!
FAQ
What exactly is a PostgreSQL index?
A PostgreSQL index is like a roadmap for your data. An index creates that alphabetical organization for your database columns, allowing PostgreSQL to jump directly to the data you need instead of reading every row.
How do I create a basic PostgreSQL index?
Creating an index is straightforward with the CREATE INDEX command. Here are the most common patterns:
1
-- Basic single-column index
2
CREATE INDEX idx_customers_email ON customers (email);
3
4
-- Multi-column index (column order matters!)
5
CREATE INDEX idx_orders_customer_date ON orders (customer_id, order_date);
6
7
-- Create index without blocking your application
8
CREATE INDEX CONCURRENTLY idx_products_price ON products (price);
The basic syntax is: CREATE INDEX index_name ON table_name (column_name). Always use descriptive names and consider adding CONCURRENTLY for production databases.
How many indexes should I create on a single table?
There's no magic number, but focus on quality over quantity. Start with 3-5 indexes based on your most common queries. More indexes slow down INSERT/UPDATE operations, so only create indexes that provide measurable performance benefits. Monitor usage with pg_stat_user_indexes and remove any that aren't being used.
Why isn't PostgreSQL using my index even though I created one?
Several reasons: the table might be too small (PostgreSQL prefers table scans for small datasets), your query might not match the index structure, or statistics might be outdated. Run ANALYZE your_table to update statistics, and use EXPLAIN to see the query planner's decision-making process. Sometimes PostgreSQL is actually making the right choice. Trust but verify with performance measurements.


