intro
Why can’t we just have a single table? Navigating relationships in relational databases.
Has this ever happened to you? You are excited to start a new project using data from an unfamiliar relational database. After getting access to the database itself you realize the quality of the documentation is poor — or the documentation is nonexistent. Now you are wondering how to join tables together to create a usable dataset.
Sound familiar? The good news is that it is easy to figure out how to join your tables together using an entity-relationship diagram (ERD), a diagram that shows how tables are related to each other. I have even more good news. It is quite simple to generate an ERD using a tool like DbVisualizer. Let’s take a look.
Creating an ERD
The Database
NOTE: The SQLite database used in this article, student_records.db, can be found here on GitHub.
Let’s consider a small sample of fictitious data on students currently enrolled in a hypothetical college (student names resembling real persons are entirely coincidental). These data are stored across four tables in a relational database named student_records. The individual tables — student_courses, students, courses, and grades — are shown below. Each table has two to three columns of data, referred to from here on out as attributes, and anywhere from four to 16 records (i.e., rows).
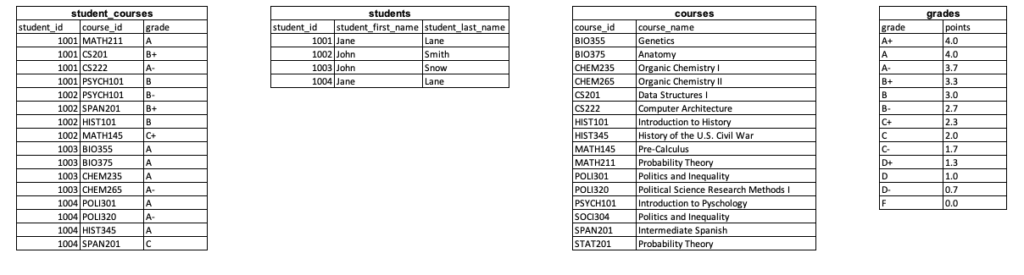
This database is small, so it is easy to see how the data can be joined by looking at the tables. For example, let’s say we want to output a table that includes all the information in the student_courses table as well as each student’s first and last name. Below is a visual description of this join process for a single student_id value.

Of course, databases in the real world are seldom as simple as this example, so it is beneficial to learn how to generate and read an ERD. Indeed, an ERD is like a treasure map to joined data!
Using DbVisualizer to Generate an ERD
If you have not done so already, download and install DbVisualizer. In addition, if you have not downloaded the SQLite database from GitHub, go to this GitHub repository and either clone the entire repository or download student_records.db.
After opening DbVisualizer, navigate to “Tools” and then click “Connection Wizard…” from the drop-down menu. In the next window, name the connection student_records and click the “Next” button. Now, select “SQLite” from the driver dropdown menu and click “Next.” Then, navigate to “Database file name” in the “Database” section of the proceeding window. Click the down arrow button to the right of mysqlite.db (if this button does not appear double-click the text box containing mysqlite.db), find the student_records.db file on your machine, and select the file. Click the “Finish” button.

Next, navigate to the tree on the left side of the window and expand the items under the new database connection (on my machine it is student_records) until you see “Tables.” Right-click “Tables” and select “Open in New Tab.” In the new tab that opens, click on the “References” sub-tab.
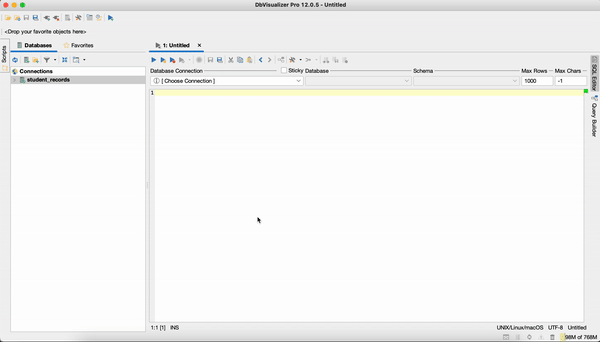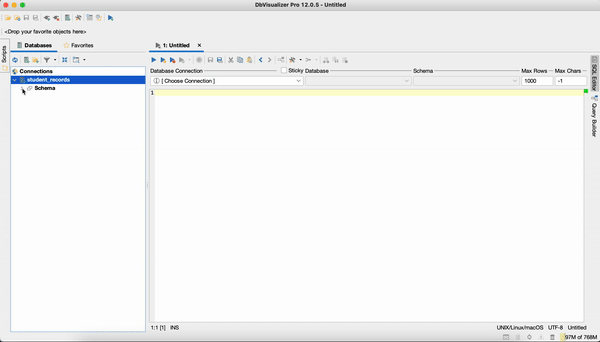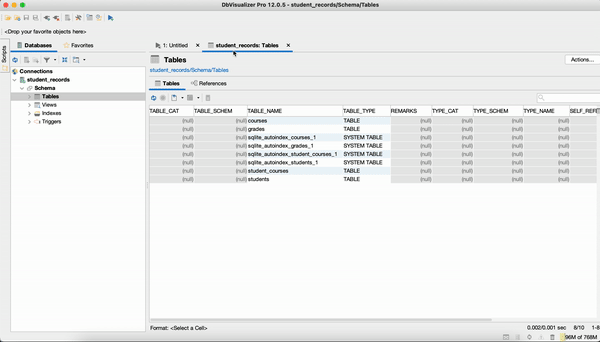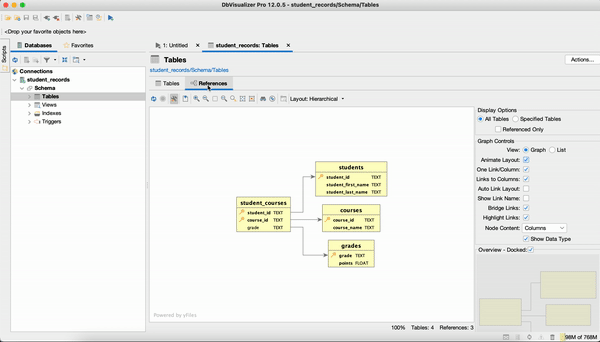
The ERD (shown below) visualizing the relationships in the student_records database will appear.
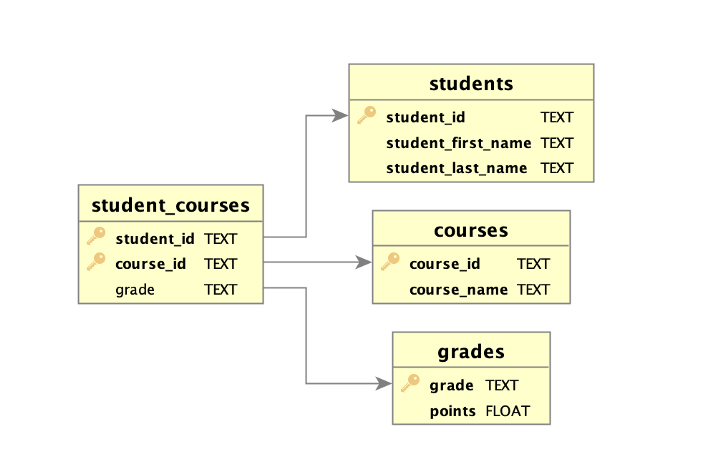
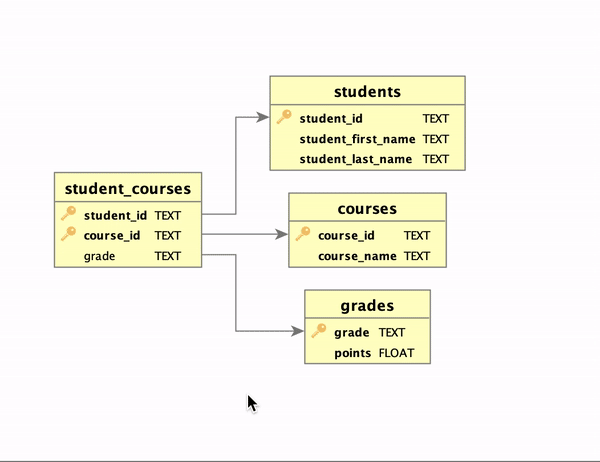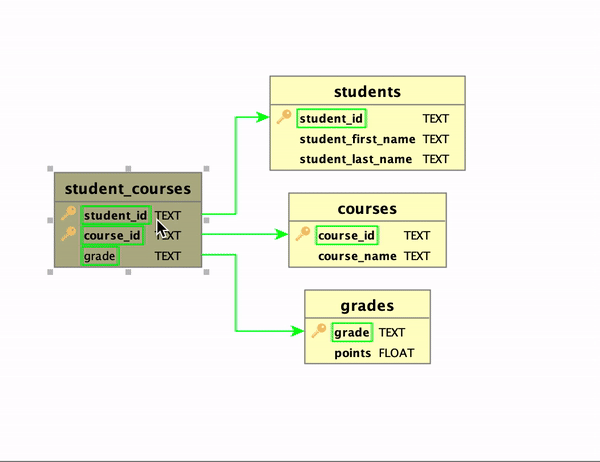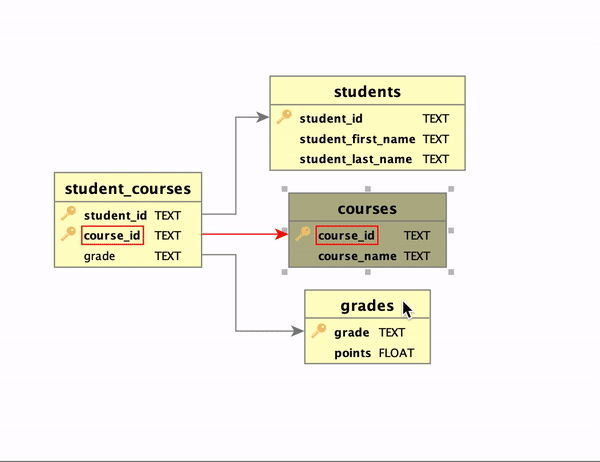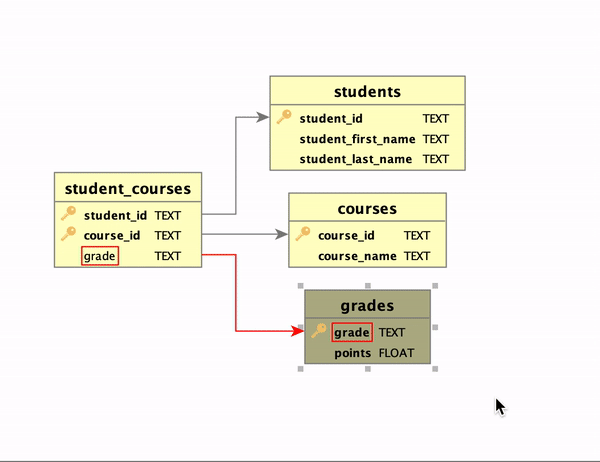
If you click on a given table in the ERD the relationship paths will be highlighted. For example, if you click on student_courses you will see that student_courses has relationships to students, courses, and grades through student_id, course_id, and grade, respectively. Thus, student_id can be used to join the student_courses and students tables, for instance. Likewise, clicking on the students table shows that students and student_courses are related through the student_id attribute (I will explain the different colors for the links in the next subsection).
Additional Considerations
There are a few additional points worth discussing. First, notice the key icons to the left of various attribute names. These icons identify the primary keys in the tables. In a relational database the attribute, or set of attributes, used to uniquely identify records is called the primary key. A related concept is that of the foreign key, which is an attribute in one table that is a primary key in another table. As such, the primary and foreign keys form a blueprint for joins.
Second, note that the student_courses table has two key icons because the primary key in that table is a composite of student_id and course_id. Neither student_id nor course_id are sufficient for identifying unique records in this table. Rather, the combination of student_id and course_id uniquely identifies each record in the table.
Third, when a table containing foreign keys is selected (e.g., student_courses), the outbound links to the related tables will be in green. Conversely, when a table referenced by other tables’ foreign keys is selected, the inbound links will be colored in red. Bidirectional links, if present, will appear in orange.
Fourth, the ERD generation feature in DbVisualizer only works if primary and foreign keys are identified when creating tables. Consider the SQL code below used to create the student_records database.
1
CREATE TABLE student_courses (
2
student_id TEXT NOT NULL,
3
course_id TEXT NOT NULL,
4
grade TEXT NOT NULL,
5
PRIMARY KEY(student_id, course_id)
6
FOREIGN KEY(student_id) REFERENCES students(student_id)
7
FOREIGN KEY(course_id) REFERENCES courses(course_id)
8
FOREIGN KEY(grade) REFERENCES grades(grade)
9
);
10
11
CREATE TABLE students (
12
student_id TEXT NOT NULL,
13
student_first_name TEXT NOT NULL,
14
student_last_name TEXT NOT NULL,
15
PRIMARY KEY(student_id)
16
);
17
18
CREATE TABLE courses (
19
course_id TEXT TO NULL,
20
course_name TEXT NOT NULL,
21
PRIMARY KEY(course_id)
22
);
23
24
CREATE TABLE grades (
25
grade TEXT NOT NULL,
26
points FLOAT NOT NULL,
27
PRIMARY KEY(grade)
28
);
In this code, the primary and foreign keys are established at the end of each code block creating each individual table. Unfortunately, if your tables were not created with the primary and foreign keys identified then you will be unable to generate the ERD.
Why So Many Tables?
At this point, if you are like me when I was learning SQL you may be asking, “why do we even need to have data spread across multiple tables in the first place?” The answer is normalization, a data storage practice that helps to ensure data integrity by preventing data redundancies and protecting against various anomalies when altering tables. Normalization is enforced through normal forms, of which the first three are particularly important.
To illustrate the normalization process say that our example database was initially stored as the single table shown below.
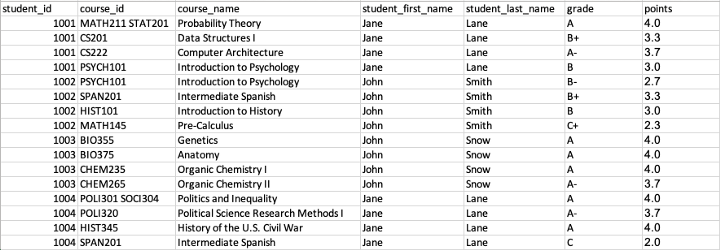
Notice that some cells under course_id contain multiple values. Think of these as courses that are cross-listed across multiple departments. Unfortunately, with multiple values in one cell, it is not clear as to which listing is the listing for which the student actually registered, which brings us to the first normal form.
First Normal Form (1NF)
The first normal form stipulates that cells should store single values that cannot be subdivided further. Our example table can be made 1NF compliant by ensuring that the actual course identifier for which a given student enrolled is recorded under course_id.

Second Normal Form (2NF)
To be 2NF compliant, a table must be 1NF compliant and all attributes that are not part of the primary key must be dependent on the entirety of the primary key. At this point, our primary key is the combination of student_id and course_id. Consider that the attribute grade is dependent on both student_id and course_id. That is, a value recorded in a grade cell does not refer to an individual student alone, nor an individual course alone, but a given student in a given course. Conversely, student_first_name and student_last_name only depend on the value in the student_id attribute. Stated differently, knowing a course_id value is unnecessary to ascertain a student’s first and last name. Likewise, course_name is dependent only on course_id.
Now you ask, “what harm could come of keeping the table structured as is at the point?” Say one of the students changes their name. For instance, student 1004’s name changes to Jane Smith. In this database there are four records that need to be updated. However, a mistake is made and student 1004’s last name is not updated in the record for HIST345. Now there is inconsistent data in the table.
To make this table 2NF compliant, we need to break the table up into three tables. The first table, student_courses, is identical to the 1NF compliant table except for the removal of the student_first_name and student_last_name attributes.

The second and third tables, students and courses, are shown below.


Notice that this change stores data more efficiently. For example, because the course information is not included in students table, we only need a single record for any student’s first and last name. Even more, if a student’s name changes there would only be one record that would need to be changed, as opposed to four.
Third Normal Form (3NF)
A table is normalized to the third normal form if the table is 2NF compliant and is free of transitive functional dependencies. In the context of relational databases, a transitive functional dependency occurs when an attribute is dependent on the primary key through another attribute that is not part of the primary key. Let’s refer to the student_courses table again.
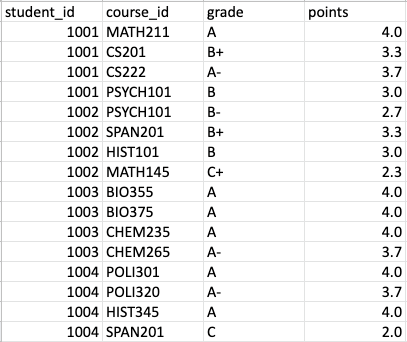
Here, grade is dependent on student_id and course_id. Furthermore, the grade value determines the points that the respective course contributes to the student’s grade point average (GPA). Put another way, if the letter grade changes, the points should change. Thus, points is dependent on student_id and course_id through grade.
Why is the situation described above an issue? The grades in student_courses range from A to C. Accordingly, there is no information in the database on the points that could be given to students who earn an A+ or a grade between a C- and F. Similarly, there is no way to tell if grades of A+ or C- to F even exist at this college in this case.
Another issue to consider is one where a student’s grade is changed. Perhaps the instructor of the course forgot to consider one of the student’s assignments and the student receives a C. The student challenges the grade, the mistake is discovered, and the letter grade is changed in the database. Unfortunately, whoever updates the database forgets to change the points for this record and the student’s GPA remains unchanged in the end.
The solution? Divide student_courses into two tables. The first table — student_courses — is identical to the 2NF version of student_courses except for the removal of the points attribute.

The next table — grades — contains each unique letter grade value and the associated points. Now we have a database that is normalized up to the third normal form.

It is also worth noting here that the establishment of the 3NF student_courses and grades tables results in more efficient data storage. Indeed, imagine a table with far more students and courses. There would likely be many records with the same letter grade and, consequently, same point values. By creating the grades table and removing the points attribute from student_courses, fewer points values need to be stored.
Conclusion
Normalized relational databases introduce a certain tension between data integrity and usability. Normalization provides protections against messy and inefficient data storage techniques, as well as unintended outcomes resulting from changes to a table. However, obtaining a usable dataset from a normalized database requires work, namely, joins. Fortunately, ERDs can be enormously helpful in understanding how to execute joins in a database, and using DbVisualizer makes the ERD generation process simple.
I hope you found this article helpful. Keep following Promotable and look for additional content in the future. Want to connect? Feel free to follow me and/or connect with me on LinkedIn. Thanks for reading!

